
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、本日の記事は、縦持ちデータの解析で使える、グループごとの解析結果を取り出す方法についてご紹介したいと思います.サブグループごとの集計については別の記事も参照ください.
一人複数行のデータやあるサブグループにおいて、2つの変数の換算をOrdinary least squares regression, Deming’s regression, linear mixed effect modelsなどを行ってそれぞれの人やサブグループに推定値を返したい場合、ちょっとした工夫が要ります.
1.1人複数行の2変数の関係を対象者ごとにまとめる
自作のデータですが、3人の対象者からそれぞれ9回のVisitごとにa, bというパラメータを取得したとします.このときこの2変数の間には線形の関係があるのではないか、と考えてそれぞれの対象者の回帰直線を引いて傾きと切片を求めることを思いついたとします.
clear
input id visit a b
1 1 45 980
1 2 55 890
1 3 60 780
1 4 66 700
1 5 70 620
1 6 75 700
1 7 88 600
1 8 90 550
1 9 97 500
2 1 40 900
2 2 55 800
2 3 64 780
2 4 66 740
2 5 75 690
2 6 80 620
2 7 88 560
2 8 91 500
2 9 90 450
3 1 40 900
3 2 50 890
3 3 56 820
3 4 60 800
3 5 67 720
3 6 70 720
3 7 80 700
3 8 86 650
3 9 97 500
end これをまずは個人を無視してただ単純に変数a, bの関係を散布図で表すと以下のようになります.
twoway scatter b a || lfit b a, legend(off)
regress b a 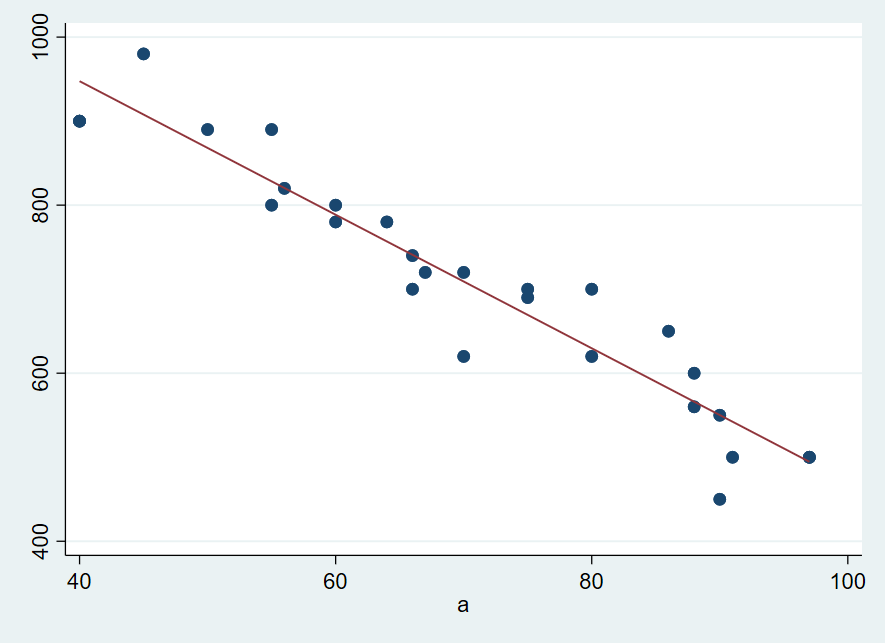
確かに線形な関係にありそうですが、3人のデータを合わせてしまっているので別々に検討する必要がありますね.そこで、
#delimit;
twoway scatter b a
||
lfit b a if id ==1, lcolor(navy)
||
lfit b a if id ==2, lcolor(maroon)
|| lfit b a if id ==3, lcolor(green)
legend(col(1) order(2 "ID=1" 3 "ID=2" 4 "ID=3") pos(3) ring(0)) ytitle(b)
;
#delimit cr
bysort id : regress b a 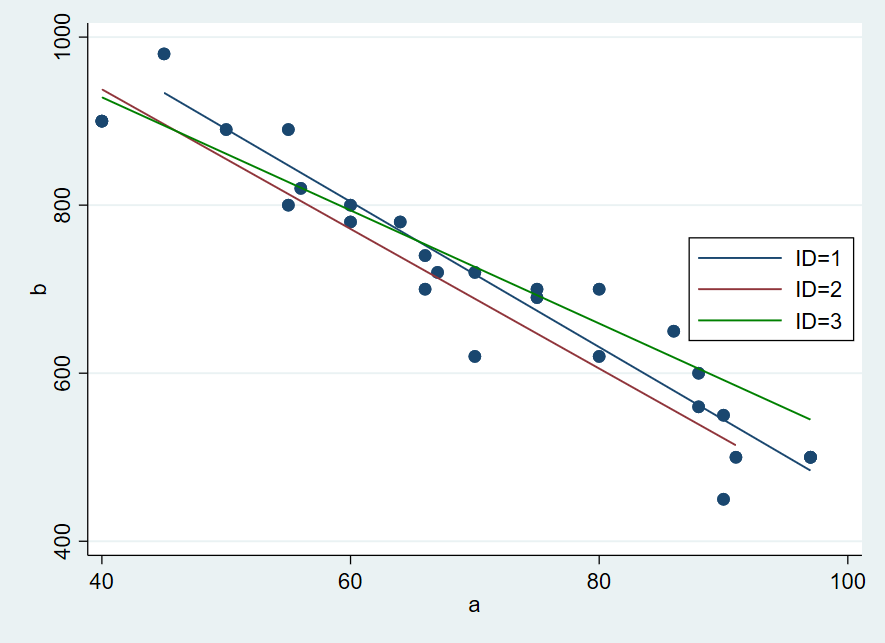
これが3人なのでまだいいんですが、コホート研究などでは数千人、数万人のデータがあるわけで、一人ひとりの推定値を転記していたら日が暮れてしまいます.
2.”statsby” を使う
これが最もオーソドックスな方法です.欠点としては元のデータを塗り替えてしまうためメモリからデータが消えてしまうことと、わざわざ新しいデータセットに保存しなければならないということがあります.しかしこれでしたらほとんどの回帰分析に対応していますので便利です.
statsby, by(id) clear: regress b a これにより無事に3人の回帰係数と切片が入手できます.
| id | _b_a | _b_cons |
| 1 | -8.646275 | 1322.833 |
| 2 | -8.307389 | 1270.166 |
| 3 | -6.730134 | 1197.607 |
汎用性の高い方法ではあるのですが、同じスプレッドシート上に推定値が入ってほしいところです.
3.”asreg”を使う
ユーザーコマンドなのでいつものようにfindit asregとするか、scc install asregとしていただく必要があります.パキスタンの先生がやっているみたいで、ほかにもコマンドがいくつか紹介されています.Stata愛を感じますねぇ(笑) 軽くシンパシーを感じてしまいます.
これはOLSしかできないのですが、同じシートの中に回帰式の計算結果を表示できるという点でちょっと便利です.ただし、繰り返しになりますが、OLSしかできないことにご注意ください.

asreg b a, by(id) 
きっちり結果が同じテーブルの上に表れているじゃあありませんか!
ということでこれはこれで便利だと思います.
まとめ
グループごとに結果を取り出す方法として、statsbyとasregをご紹介しました.
前者は汎用性の高いプログラムですが、データセットが消えてしまう、新たなデータをセーブする必要がある、という面倒を抱えています.後者はOLSだけですが、使い勝手は良さそうに思います.
個人の腎機能の低下率を計算する方法として混合効果モデルとともにOLSが使われますが、そんなときに使えるコマンドだなぁと思いました.誰かの役に立てば幸いです.


コメント