
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、記事を更新しないまま何と1年も経過してしまいました. しかし信じられないことに、ほぼ毎日100~200名の方がこちらのブログに訪れてくださっていました!
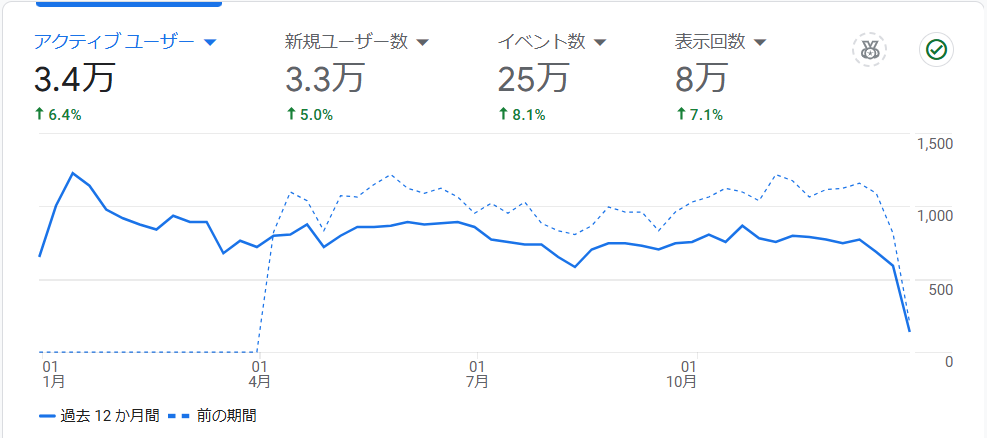
しかし、記事の更新が滞ると閲覧者は徐々に減っていくことがよくわかります.前年と比べると1~2割減少していることがわかります.ブログの広告収益も減っています(泣笑).
毎年コンスタントに10000円程度あったのが、6000円まで減ってしまいました.レンタルサーバー代が毎年13000円ほどかかりますので、赤字です.
ということで、今年はもう少しブログ作成の頻度を上げていこうと思います.
さて、今年の記事は、しばらく予測モデルについて調べたことを小出しにしていこうと思います.
以前も予測モデルに関しては記事を書いているのに、なぜ今更予測モデルなのか?
それは、近年また予測モデルがアツイからです.この話題は2024年、複数の学会でとりあげられていました.
昨年参加したヘルスデータサイエンス学会の学術集会に参加した際に統計数理研究所の野間先生がレクチャーをされており、大変勉強になりました.
なお、本稿の執筆において参考としたのは、その野間先生のレクチャーで紹介されていた下記論文
Developing clinical prediction models: a step-by-step guide. BMJ 2024;386
それと、こちらの書籍になります.
こちらの書籍は思ったより分厚かったです(笑)
しかし内容がかなり詰まっているので、特に気になるところを読んでみる感じで購入されてはいかがでしょうか?厚みの分内容が濃い分、値段もそれなりですが、購入する価値ありです!
予測モデルですが、同じ事象を予測するはずの予測モデルにおいても、異質性が大きいことが多く、またその方法論が標準化されていないことが問題でした.
BMJの論文は非常に明快にわかりやすく書かれており、最初に手に取るのによいかなと思います.
1.予測モデルのオーバービュー:13 Stepsで紐解く予測モデル研究
まず、Figu 3にある予測モデルの全体像を示してみましょう.論文はOpen accessで適切に引用があれば許可不要とのことでしたので、堂々と載せていきます.

これだけだと何のことかわかりませんので、もうちょっとかみ砕いていきます.
| Step | 説明 |
| Step 1. 目的の明確化 | 対象集団、アウトカム、セッティングや予測モデルを利用する人、モデルから意思決定を行うことを考える.臨床医、統計家、利用者を交えること.既存モデルや予後因子に関する研究を見つけておく.プロトコル作成を. |
| Step 2. 新規モデルの作成か、既存モデルの更新か | 外的妥当性検証か、既存のモデルを更新するかを検討する. |
| Step 3. アウトカムを決める | 連続値なら連続値のままがよく、無理に二値化することは避ける.生存時間分析を優先する. |
| Step 4. 候補となる予測因子をリストアップ | 既存の知識やエキスパートの意見に基づき候補を挙げる.因果的な要因を挙げる.二値化は避ける. |
| Step 5. データ収集 | 測定誤差について検討する.予測因子の分布や欠測を確認する. |
| Step 6. サンプルサイズ設計 | サンプルサイズ計算により標本集団の最低限の数や予測因子をどこまで入れられるかが決まる. |
| Step 7. 欠測値への対処 | 欠測を予測する因子を検討する.多重または単一代入を行う. |
| Step 8. モデルの当てはめ | 「縮小推定」を用いる.単変量での確認は避ける. |
| Step 9. モデル性能の確認 | 判別 Discrimination、較正 Calibrationを評価する.内的妥当性の検証を行う. |
| Step 10. 最終モデルの決定 | ”オプティミズム”で補正したモデル性能を行う. |
| Step 11. Decision curve analysisの実施 | net benefitを計算して単純な意思決定と比較優位性を検証する. |
| Step 12. 個別の予測因子の予測能を評価 | (オプション) |
| Step 13. 論文執筆&エンドユーザー向けに | TRIPOD声明に則って論文を執筆する.エンドユーザーのユーザビリティを高める工夫をする. |
いくつか気になるフレーズが出てきましたね.
2.各論で扱う事項について
アウトカム指標としては連続値は連続値のままで使用するし、二値アウトカムであれば生存時間分析を優先しなさい、とあります.
二値でやる方が統計的にはやりやすいのは事実なんですよね.ロジスティック回帰からAUCやらcalibration plotなんかもやりやすいですし.でも生存時間分析でのやり方は以前にも紹介していました.
欠測値の補完についてはmultiple imputationでもsingle imputationでもよいようです.
ただしsingle imputationも単純に平均値を代入するとかはよくありません.
Step 8にでてきましたが、Shrinkage=「縮小(推定)」とは一体なんのことでしょうか?
Stepの中では細かく触れられていませんでしたが、様々なモデル・手法がありますので、これらについても追々記事を作成してまいります.
様々な手法を駆使していってもOver fittingの問題は常に付きまといます.これに関するわかりやすい図がありました.
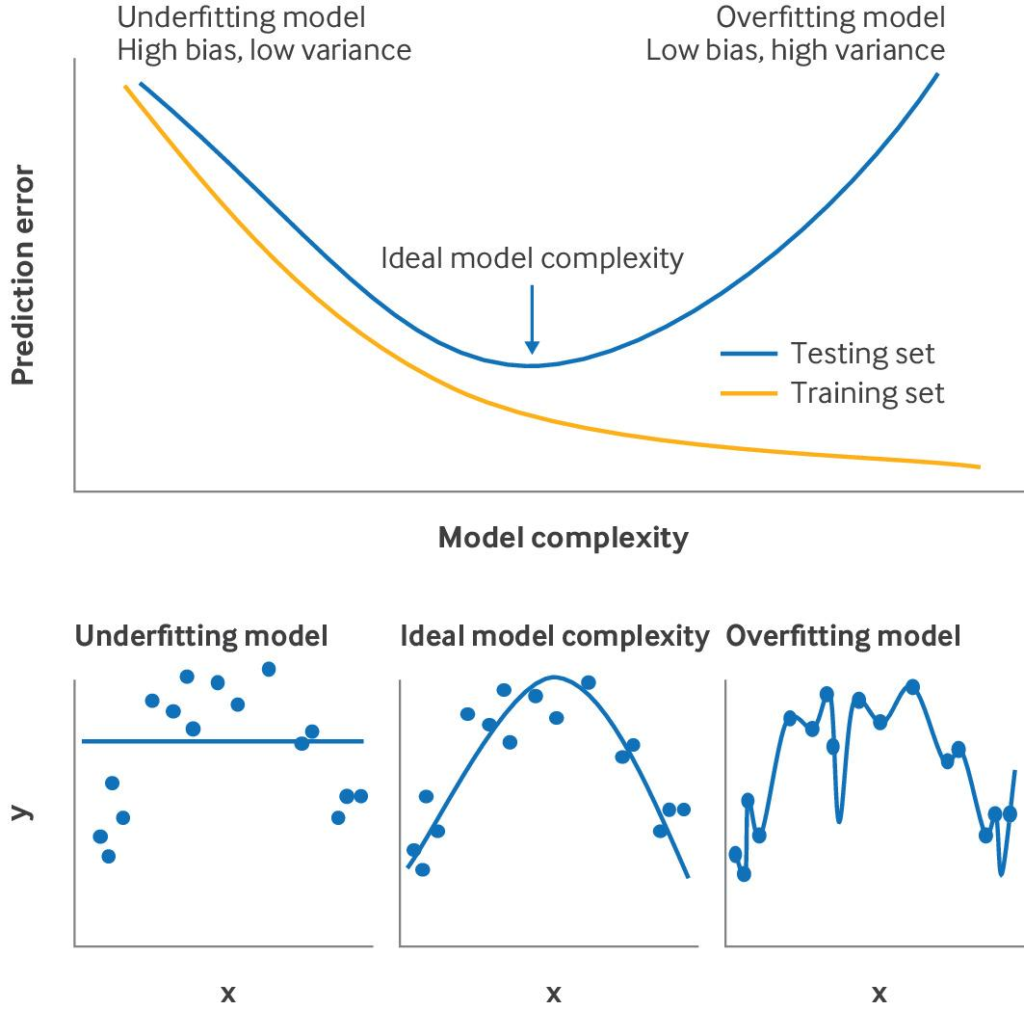
そして、聞きなれない単語「オプティミズム」などというフレーズがでてきました.これが一体何を意味するのでしょうか?
これらについて各論で詳しく説明したいと思います.


コメント