
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
今回はStataプログラミングに関してです.
縦持ちの検査データをクリーニングしているときに、欠測値の処理方法に困ることがあります.
具体的には「<1.0」とか、「<0.58」とか、「測定感度未満」といったフィールドが混在している場合なんですが、皆さんならどのように対処していますか?
- 測定感度の下限値を入れる
- 欠測扱いにする
- その他
特に2を選択した場合が問題です.
なぜなら「<0.1」「測定感度未満」などとフィールドに入っているとそのフィールド全体が文字列として認識されてしまうので、numericにしようと
destring varname, force
としてしまうとこれらはすべて情報を含まない欠測として処理されてしまいます.
これら測定感度未満のレコードは「測定は行った」という情報を含んだ欠損値となるわけですね。なので、「測定すら行っていない」人とは区別したくなります.
Stataでは欠損値を . (ドット?ピリオド?)で表現しますが、このような意味的な区別をつけるために 「.a」、「.b」、「.c」のように表現することができます.
これは文字列とは認識されず、numericのフィールドに入れることができます.
UCLAのサイトには「99」とか「999」といった欠損パターンをStata流の欠測記号に置き換える方法が紹介されていますが、現実のデータはこんなにお行儀がよくないことも多々あります.
(データセンターがきちんと機能して、出来のいいEDCを作るとこういう値を用意してくれたりするかもしれませんが…)
現実のデータですので、様々な欠測のパターンがあり得ますが、これらをひとまとめにして感度以下としたいときには次のような手順で処理してみてはどうでしょうか.
- 最初に欠測のない検査値をnumericにして別変数を作成
- 元の変数の欠測パターンをlevelsofで一括してlocal変数として抽出
- for構文でこれらのパターンをすべて新しい欠測である .a と置き換える
具体的なコードは以下のような感じです.
destring 検査結果値, generate(results) force /* STEP1: 欠測のない検査値だけでresultsという新変数作成 */
levelsof 検査結果値 if results==., local(levels) /* STEP2: 欠測のパターンをlevelsofで呼び出してlocal変数に格納 */
foreach v of local levels {
replace results=.a if 検査結果値=="`v'"
} /* Step3: .aに置き換える */簡単な例題をご用意しましたので、Do-fileに適宜コピーして試してみてください.
input id strL 検査結果値
1 1
2 2
3 3
4 "<0.1"
5 5
6 "<0.1"
7 測定感度未満
8 "<0.3"
9 9
10 "<0.5"
end
destring 検査結果値, generate(results) force
levelsof 検査結果値 if results==. , local(levels)
foreach v of local levels {
replace results=.a if 検査結果値=="`v'"
}do-fileにコピーするときに「記号のミス」と「全角スペースの混入」が一番多い失敗原因ですので、参考になればと思います.
(4/10追記)
さて、上記の方法では測定感度未満をすべて等しく .a に置き換えています.しかし、それも異なる欠損値として処理したい場合には以下のコードで実行可能です.
input id strL 検査結果値
1 1
2 2
3 3
4 "<0.1"
5 5
6 "<0.1"
7 測定感度未満
8 "<0.3"
9 9
10 "<0.5"
end
** 文字列を欠損扱いするパターン(もともとの欠損なのか、文字列だったのかの区別は付かなくなる)
destring 検査結果値, generate(results) force
replace results=.a if results==.
** 文字列をそれぞれ区別するパターン
destring 検査結果値, generate(results2) force
levelsof 検査結果値 if results2==. , local(levels)
local alphabet = "a"
foreach v of local levels {
replace results2=.`alphabet' if 検査結果値=="`v'"
local alphabet = char(ceil(strpos("`c(alpha)'", "`alphabet'")/2) + 97)
}
list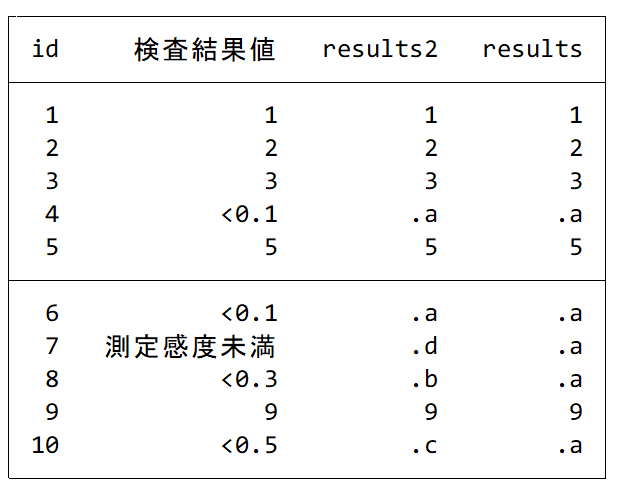
ここで、c(alpha)というのをdisplayすると、a b c d…x y zという文字列が出てきます.
直前に来ていたアルファベットが何番目に出現するかをstrpos()という関数が計算してくれます.このc(alpha)がスペースで区切られているために2で割って繰り上げ、という一手間をかけています.
char()というのは、何らかの文字と番号を対応させるのに使える関数と思っておいてください.
forvalues n = 33/126 {
disp `n', char(`n')
}と入れてみたら、全貌が明らかになります.とにかく、97以降が小文字のアルファベットであることを押さえておけばここはクリアです.
そんなややこしいこと考えたくない、という場合にはループ以下を次のように書き換える事も可能です.
char(97)=aなので、ループのたびに98,99,100,… と番号が積み重なっていくことになります.
foreach v of local levels {
replace results2=.`alphabet' if 検査結果値=="`v'"
local alphabet = char(strpos("abcdefghijklmnopqrstuvwxyz", "`alphabet'") + 97)
}

コメント