
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、これまで縦持ちデータをどうやってうまくハンドリングするかについて、たくさん記事を書いてきましたが、横持ちデータもそれなりに需要があるよな~と思い、記事を書いてみることにしました.
もっと基本的な縦持ちデータの扱いについてはコチラ
横に連なるデータであっても、結構扱いに困るような場面もあり、そんな場合の一工夫はコチラ.
過去の記事もたまに見ると勉強になるもんですねえ…。
さて、今回想定しているのはこんな場面です.
あるコホート研究で、様々な有害事象を追跡するという類のものだと想定します.
イベントの種類は種々雑多なもので、以下のように例えば定義されていたとしましょう.
- 1:低ナトリウム血症
- 2:低カリウム血症
- 3:高カリウム血症①≥5.5
- 4:高カリウム血症②≥6.0
- 5:急性腎障害
データセットはイベントを横に並べていくスタイルだとしましょう.
| ID | exposure | event1 | date1 | event2 | date2 | event3 | date3 | event4 | date4 |
| 1 | 1 | 1 | 4/3 | 2 | 5/3 | 1 | 5/7 | 4 | 6/23 |
| 2 | 0 | 4 | 4/9 | ||||||
| 3 | 0 | 3 | 6/30 | 5 | 6/30 | 1 | 7/4 | ||
| 4 | 1 |
1:低ナトリウム血症
2:低カリウム血症
3:高カリウム血症①≥5.5
4:高カリウム血症②≥6.0
5:急性腎障害
このような状況ですと、同一のイベントが繰り返し起こることもあるし、イベントごとに整理するのも苦労しそうです.
解析の仕方に応じてデータの加工を考えるのが理にかなっていますので、いくつかのパターンに分けて考えていきます.
1.特定のイベントに着目する場合
例えば1の低ナトリウム血症にだけ興味があったとします.そのときには特定のイベントだけ取り出してくればよいことになりますので、一度データをlong形式にするのが手っ取り早いでしょう.
イメージとしては、まずイベントだけの縦持ちデータにし、そして気になっているイベントだけを残し、後から元のデータに再結合するというものです.
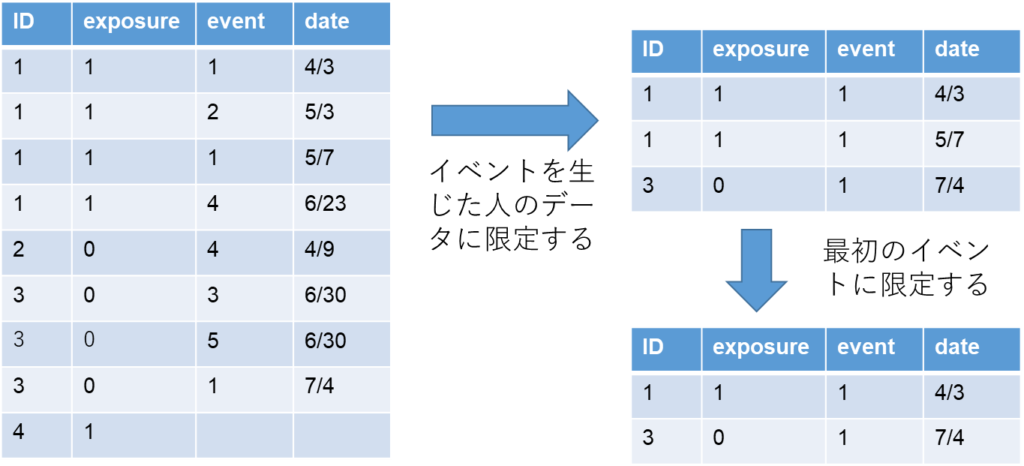
右下の表を元の横持の表からイベントデータを抜いたデータセットにマージします.
カウントデータが欲しい場合には右上の表の状態で、IDごとの行数を右側にでも新たな変数として結合することで解決します.(egenコマンドで、countという関数を使えば簡単です)
2.複数のイベントの着目する場合
基本的には同じ作業を繰り返せばよいのですが、いちいち面倒くさいなあという感じがします.
それぞれのイベントの回数がわかればいい場合などはegenコマンドのanycountという関数で一発で解決してしまいます.
.egen hypona_time = anycount(event*), values(1)
と入れてしまえば、低ナトリウム血症を表す、1がevent1~event4の中に入っている回数をカウントしてくれます.
これのいいところは、eventがワイルドカードになっているので、横にいくら長くても、同じ規則で作られた変数名であれば対応可能である点です.
同様にして異なる電解質異常について、それぞれ変数名を作成して同じようにカウントデータを得ることができます.
例えば同じイベントが複数生じているようなときに、その数を数えたかったら、
.egen time = rownonmiss(event*)
とすればイベントの数が数えられますし、最初のイベントの日付だけでよければ
.egen firstevdt = rowfirst(date*)
とすれば求められます.このデータはSurvival analysisで使えますが、先頭のイベントならdate1をとってくればよいのでは?と思われるかもしれません.
しかし例えば条件付けをしていて、何かの日付よりも後のデータだけを採用したい場合、
今回の作業の前に、条件付けでイベントのフラグをmissing にしてしまうような場合があり得ます.そんなときにはegenコマンドを使って処理すれば意外と簡単に行うことができます.
egenコマンドで横持ちデータに活用できるその他の関数をご紹介しておきます.
これらのコマンドにおいては、もし変数リストの中のどこにもレコードがなければ新しい変数には欠損値が入ります.同じ行の中で処理してくれるので便利です.これらはbyと組み合わせられません.
rowfirst(varlist):変数リストの中で一番最初にでてきた値を返します.
rowlast(varlist):変数リストの中で一番最後にでてきた値を返します.
rowmax(varlist):変数リストの中で一番大きな値を返します.
rowmean(varlist):変数リストの平均値を返します.
rowmedian(varlist):変数リストの中で欠損値以外の値の中央値を返します.
rowmin(varlist):変数リストの中で一番小さな値を返します.
rowmiss(varlist):変数リストの欠損値が入ったフィールドの数を返します.
rownonmiss(varlist) [, strok]:変数リストで値が入ったフィールドの数を返します.strokオプションがあればnumeric変数も文字列もどちらでも入っていれば欠損値ではないという扱いになります.
rowpctile(varlist) [, p(#)]:変数リストのパーセンタイル値を返します.
rowsd(varlist):変数リストのSD値を返します.
rowtotal(varlist) [, missing]:変数リスト内の値を合算した値を返します.何も値が入ってなければ0となります.ということで、横持ちデータの状態であっても割とスマートにデータ加工を行うことができるということがお判りいただけたでしょうか?egenコマンド、慣れれば意外と便利なこともありますので、積極的に使っていきましょう.

コメント