
連続変数からカテゴリー変数を作る、という方法はStataではいくつか用意されていますが、実際に使い分けがよくわからない、という声を良く聞きます.
今回は連続変数からカテゴリー変数を作る方法を整理してみたいと思います.
1.連続変数の”区切れ目”の考え方
カテゴリー化する際に、どのように“区切れ目”を決めるか、ということがまずは重要な問題です.
連続変数の区切れ目は以下のように大別されます.
- あらかじめ指定されている
- データの分布から決まる
1は臨床的な意味のある区切れ目です.
例えば成人の肥満カテゴリーがBMIによって以下のように決まっています(WHO基準).
- 18.5未満で「痩せ」
- 18.5から25で「普通」
- 25以上では「過体重」
- 30以上では「肥満」
2はバイオマーカーの研究などでよく見られたりしますが、
三分位や四分位(時に五分位、六分位)に分けて要因とアウトカムの関連を調べたりします.
2.1のsyntax例
1)オーソドックスな方法
generate bmicat = 1 if bmi < 18.5
replace bmicat = 2 if bmi >=18.5 & bmi < 25
replace bmicat = 3 if bmi >= 25
replace bmicat = 4 if & bmi >= 30 & bmi ~= .最後に”age==.” としたのは、Stataでは欠損値を無限大と取ってしまうため、「欠損値以外」という条件を追加しています.
しかしこれを一行のsyntaxでかけるとスマートですね.
2)”recode” コマンドを使用した例
recode bmi (30/max = 4) (25/30 = 3) (18.5/25 = 2) (min/18.5 = 1), generate(bmicat)ちなみに
recode bmi (min/18.5 = 1) (18.5/25 = 2) (25/30 = 3) (30/max = 4), generate(bmicat)とすると、区切れ目の位置にある数字がどちらのカテゴリに入るかは変わってしまいますので注意です.
コマンドの前に書かれた内容が優先されます.
どちらかがややこしい場合には区切れ目の数字が重複しないようにしたほうがよいですが、整数でない限りは難しいかもしれません.
サンプルデータで確認しますと、
sysuse auto, clear
recode mpg (min/18 = 1) (18/24 = 2) (24/30 = 3) (30/max = 4), generate(mpg1)
recode mpg (30/max = 4) (24/30 = 3)(18/24 = 2) (min/18 = 1), generate(mpg2)
tabulate mpg mpg1
tabulate mpg mpg2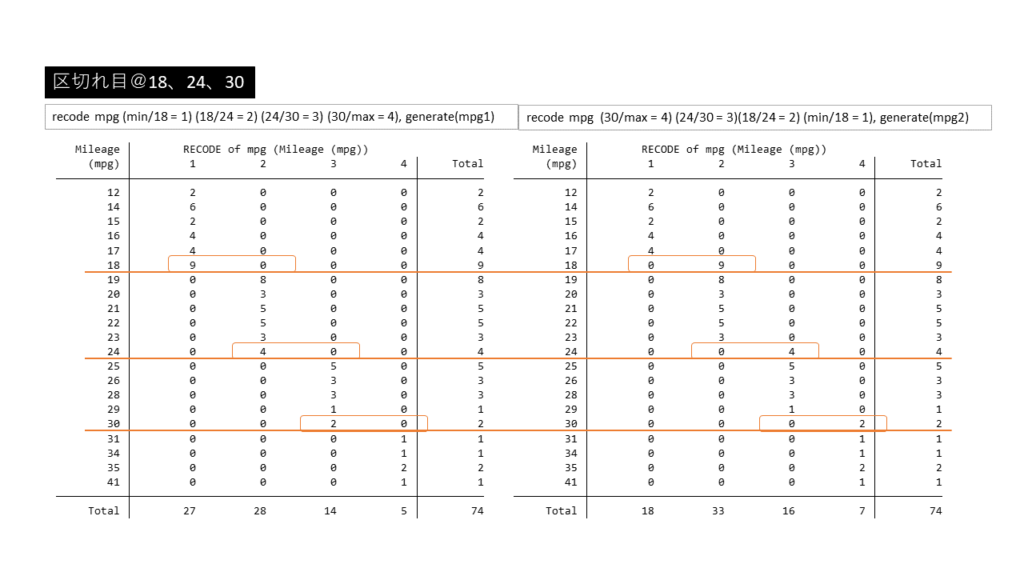
なお、この”recode”ですが、関数としても活用できます. この場合は区切れ目の数値を入れて、最小値から順番にその値までを含めたグループができます.
gen mpg3 = recode(mpg, 18, 24, 30, 41)
tabulate mpg1 mpg3このとき、グループ番号がそのグループの最大値となります. また、”irecode”という関数を用いれば全く同じ構文で同じ使い方で、欠損値も扱えるうえにグループのダミー変数が0から行儀よく付与されるという点で使いやすくなっています。
3)スマートな例
generate bmicat = (bmi < 18.5)*1 + (bmi >=18.5 & bmi < 25)*2 + (bmi >= 25 & bmi ~= .)*3 これは “if” が省略されていますが、立派な条件節として認識されます.
Binaryの場合にはさらに、以下のような書き方でもOKです.
generate obesity = (bmi >= 25) if !missing(bmi) !missing(var)を条件節に追加すると、欠損値がカテゴリ化されません.これは以下のコマンドと同義になります.
generate obesity = 1 if bmi >= 25 & !missing(bmi)
replace obesity = 0 if bmi < 25 & !missing(bmi) 3.2のSyntax例
1)xtileを用いる.
分位点で区切りを入れます.
.xtile newvar = varname, n(#) (#は分位の数)
2)egen, cutを用いる.
これも分位点で区切りますが、xtileと切れ方が若干異なります.
.egen newvar = cut(varname), group(#)
なお、分位点で分けるだけでなく、任意の点で区切ることができます.
その場合はオプションat()とし、括弧の中はコンマ区切りで任意の数字を入れます.
.egen newvar = cut(varname), at(#1, #2, #3, #4)
この場合は#1~#2、#2~#3、#3~#4 の3つの間にある値を
3グループに分けますが、イコールは小さい方の値にだけつきます.
これに対してxtileは違った分け方をするようで、境目が一致しないことがあります.
サンプルデータで確認してみましょう.
webuse lbw, clear として “lbw” という名のデータセットを使用します.
xtile age3 = age, n(3)
egen age3_2 = cut(age), group(3)
tab age3 age3_2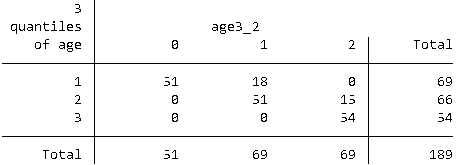
境目に多くのレコードがある場合にはこのように大きくずれることもあるので要注意です.
ところで、”egen” は初学者にとっては少しわかりにくいことがあるかもしれません.
エクセルで関数を作るときの感覚に似ていて、エクセルに慣れ親しんだ人なら比較的早く理解できるかもしれません.
どこかでこの “egen” コマンドについても紹介していきたいと思います.


コメント