
一人一行で整えられた形(Wide)にしても、一人複数行の形(Long)にしても
データセットにはある程度共通点を持ったグループであるサブグループがあり、
そのサブグループごとに集計値を出したいときがあると思います.
それだけでなく、一人複数行のデータの場合には対象者ごとの集計値を算出する場面もあるはずです.
今回はそんな場合に便利な”by-group processing”について説明します.
1.サブグループごとに結果を得る
このセクションでは、”by”という前置詞をコマンドの前に置いてサブグループを指定し、
そのサブグループごとに集計結果を得るための方法をご紹介します.
sysuse auto.dta, clear
tabulate mpg, summarize(foreign)| Car type | mean | sd | freq |
| Domestic | 19.826923 | 4.7432972 | 52 |
| Foreign | 24.772727 | 6.6111869 | 22 |
| Total | 21.297297 | 5.7855032 | 74 |
ここで、Car type(外国製か国内製か)で分けてそれぞれの集計結果を出したい場合に、
まず分けるサブグループでsortし、次に”by subgroupname: command“とします.
sort foreign
by foreign: summarize price mpg trunk weight length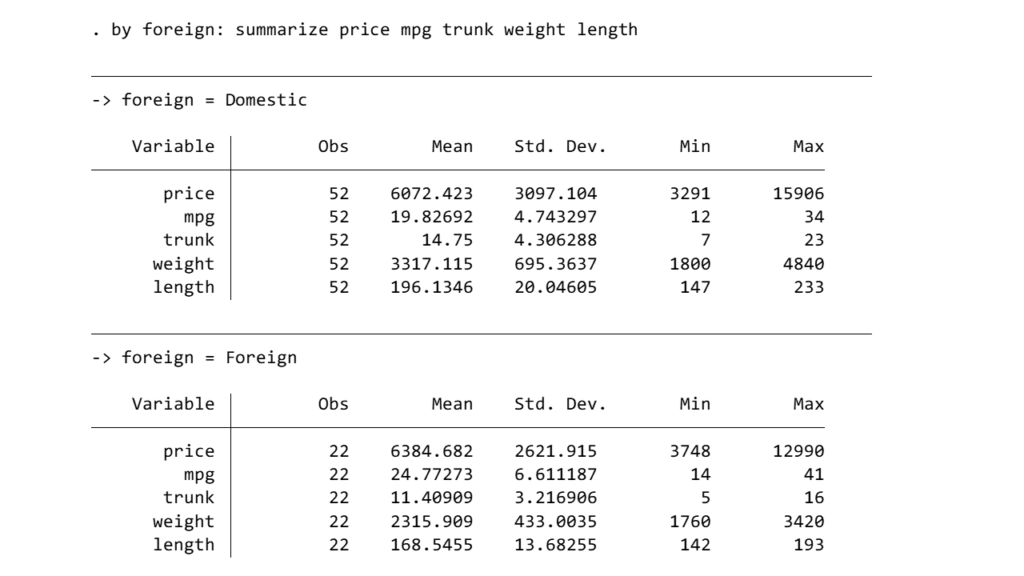
ここで、sortされていないとうまくコマンドが走らないので注意してください.
sort機能も併せ持つのが”bysort”になりますので、これを使えば事前のsortは不要です(bysと略すことも可能).
bysort foreign: summarize price mpg trunk weight lengthちなみにこのサブグループ集計は回帰分析や相関分析でも使うことができます.
サブグループごとの回帰分析の結果を表すのにforest plotを描くときなどに便利です.
2.サブグループごとに集計する
このセクションでは、サブグループごとに集計値を求めて新たな変数を作っる方法について説明します.
ここで、”egen”について簡単に説明します.
bysort foreign: egen avgmpg = mean(mpg)これをかみ砕くと、
「”foreign”のグループごとに”mpg”の平均値をとり、
新たに”avgmpg”という変数にした.」
ということになります.
このときの”mean”は関数ですが、エクセルの表計算を行うときにセルに入力する関数に似ています.
egenコマンドとともによく使われる関数を一部ご紹介します.
| 関数名 | 意味 |
| mean | 平均 |
| count | 欠損値のないレコード数 |
| min | 最小値 |
| max | 最大値 |
“census”というデータセットを使って試しに何かやってみましょう.
このデータセットは4つの地域があり、そのサブグループで人口の平均をとり、それぞれのz値を算出してみましょう.
(正規分布していないので何とも微妙ですが…)
sysuse census.dta
bysort region: egen avgpop = mean(pop)
bysort region: egen sdpop = sd(pop)
generate zpop = (pop - avgpop)/sdpop
list state region pop avgpop sdpop zpop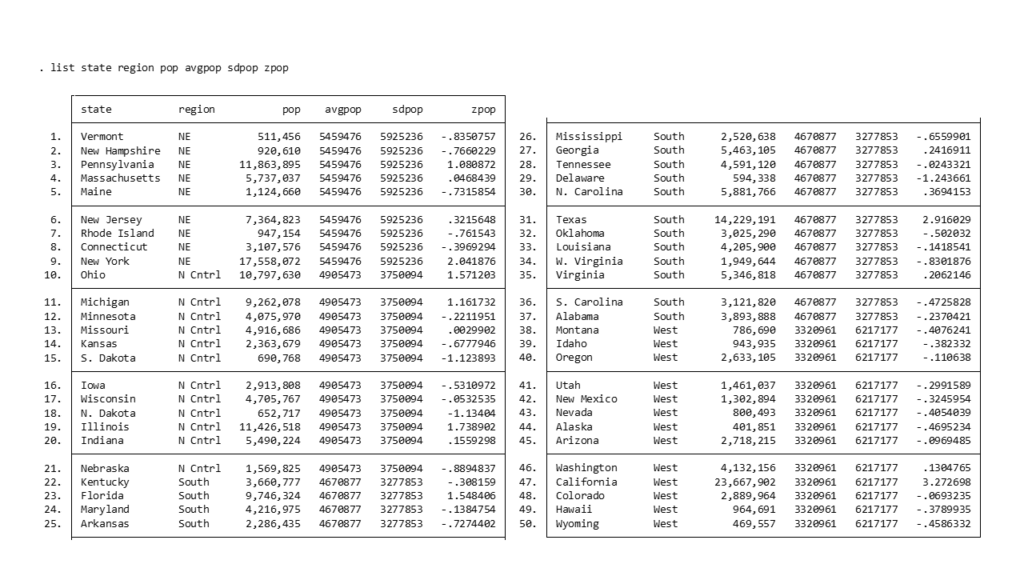
3.サブグループ内でのデータ加工
ここでは別の行の結果を使って計算する方法について説明します
この方法を熟知すると飛躍的にデータ加工の幅が広がります.
そのためにはどのように行を指定するのでしょう?
答えは簡単で、[1],[2]などのようにすれば、上から何番目かを指定できるのです.
また、一番最後の場合には[_N]となり、相対的な位置関係を示すには[_n-1], [_n],[_n+1]などのように表現します.
webuse pig.dta
bysort id: generate previousweight = weight[_n-1] /// 前回体重
bysort id: generate deltaweight = weight - weight[_n-1] /// 前回からの変化
bysort id: generate average_3recent = (weight[_n-2] + weight[_n-1] + weight)/3 /// 直近3回の平均
bysort id: generate first = (_n == 1) /// 最初かどうか
bysort id: generate last = (_n == _N) /// 最後かどうか
bysort id: generate inc30 = (weight >= weight[1] * 1.3)
/// 最初に比べて30%以上体重が増えたかどうか(1: yes, 0: no)4.まとめ
サブグループごとに集計したり、あるいはほかの行の値を使って計算することで、
縦断的な変化をみたりすることができるので、そういった解析をする場合には不可避なコマンドだと思います.
腎臓病領域だと「eGFR 50%減少」といった指標がアウトカムになりますので、
こういったデータの加工や計算に慣れておくとよいですね.
さらに詳しく知りたい方はこちら↓


コメント