
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、今回はデータ加工の中でも難易度の高い、「構造はあるけど解析に向かないデータ」を用意してみましたのでチャレンジしてみましょう.
まずはこれがどんなデータになっているのかを理解するために、データの作りがどうなっているのかを確認してみます.下のように、エクセルをインポートするふりをして中身だけ確認するコマンドがありますので、それを使ってみましょう.
*** エクセルを開かずに中身を大雑把に確認する
import excel "format_repeat.xlsx", describeこれを打ち込むとデータセットを開くことなく、
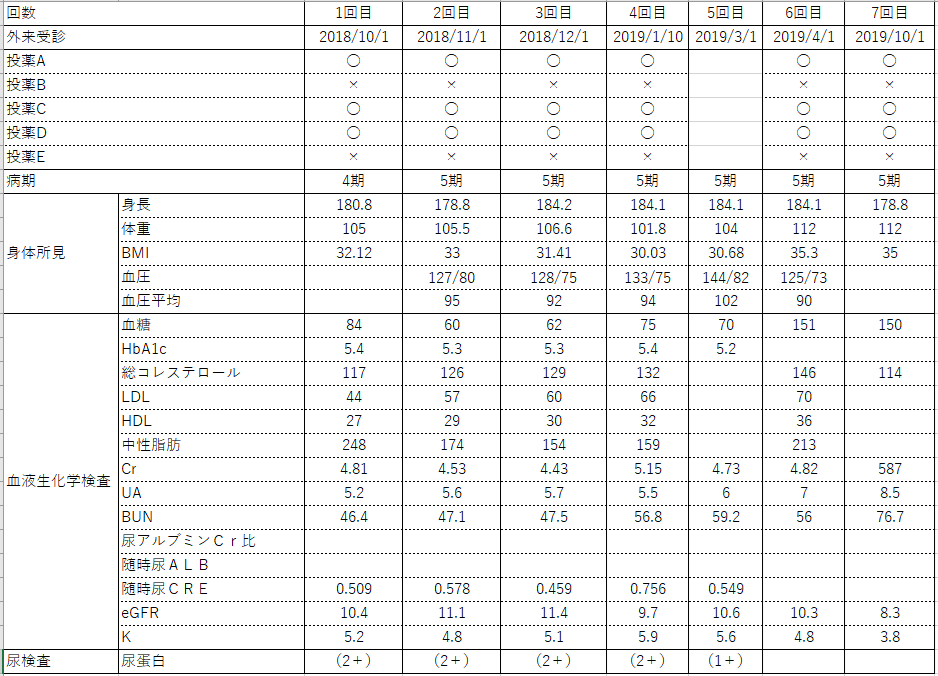
でもせっかくなのでとりあえず1枚目だけでも開いてみてみましょう.
ちなみに、describeのよいところは、初めからエクセルシートのとても容量が大きいときに役立ちます.データを直接閲覧するほうがはるかにイメージは湧きやすいのですが、重すぎて開かない!というときに、複数のシートに分割されてデータが入っていることがあって、気が付かなかったりするんです(アホみたいですが本当にあった話です。データが入ってませーんと送り先に送ったら、シートに分けてるよ、と半ばあきれられてしまったことがありました。)
さて、このデータですが、実際に渡されたデータを参考にしています.(もちろん中身は完全にダミー値です.)1人につき1シートで、150人分のデータがずーっと連なっているというデータです.
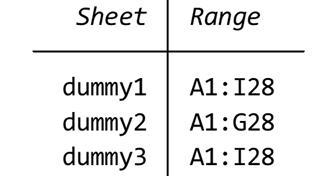
describleしたあとに、return listと入れると、スカラー値とマクロが表示されます.
return list
scalars:
r(N_worksheet) = 3
macros:
r(worksheet_1) : "dummy1"
r(range_1) : "A1:I28"
r(worksheet_2) : "dummy2"
r(range_2) : "A1:G28"
r(worksheet_3) : "dummy3"
r(range_3) : "A1:I28"
これを順番に加工します.具体的にデータセットとにらめっこしながら加工のプロセスを踏んでいきます.
import excel "format_repeat.xlsx", allstring
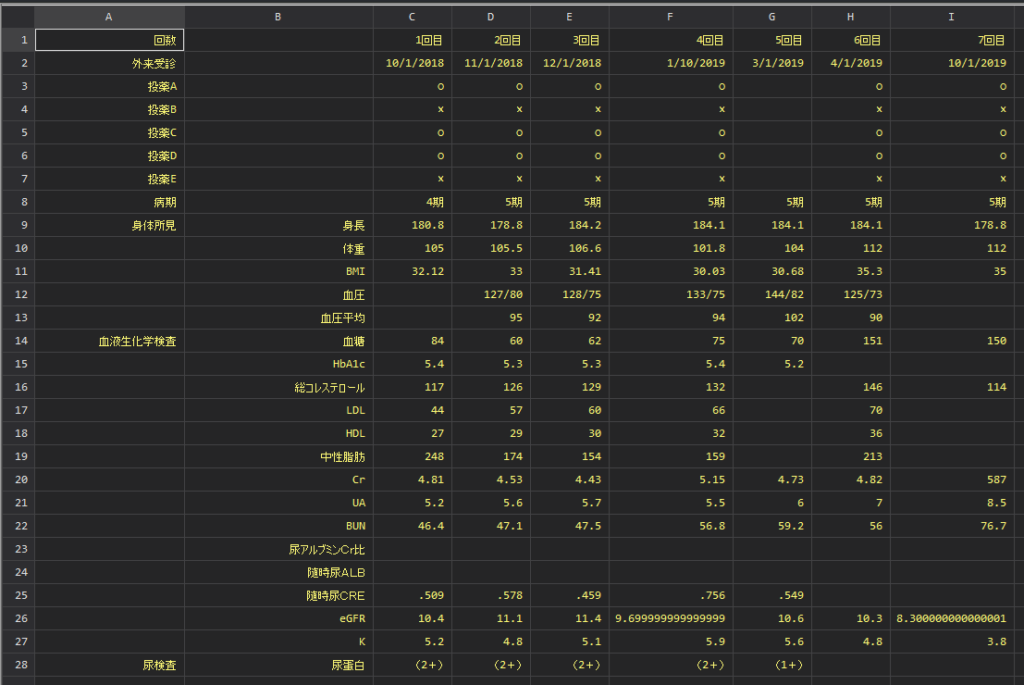
1列目と2列目に見出しがはいってしまっていますので、これを統一しなければなりません.
2列目にたくさん入っているので、それを軸にすることにします.
import excel "format_repeat.xlsx", allstring
drop A
rename B variable
replace variable = "回数" in 1
replace variable = "日付" in 2
replace variable = "投薬A" in 3
replace variable = "投薬B" in 4
replace variable = "投薬C" in 5
replace variable = "投薬D" in 6
replace variable = "投薬E" in 7
replace variable = "Stage" in 8できれば変数を横に、Visit単位のレコードを行にしたいですね.ここで、行と列をそっくりそのまま入れ替える方法(transpose)があります.
Stataでそのまま使える関数として、xposeというのがありますが、これは文字列が損なわれてしまいます.そこで、sxposeという関数を探してみましょう.
sxpose2を選択してみました.一列目の文字列を変数リストにしたいので、
import excel "format_repeat.xlsx", allstring
drop A
rename B variable
replace variable = "回数" in 1
replace variable = "日付" in 2
replace variable = "投薬A" in 3
replace variable = "投薬B" in 4
replace variable = "投薬C" in 5
replace variable = "投薬D" in 6
replace variable = "投薬E" in 7
replace variable = "Stage" in 8
sxpose2, firstnames clearとしてみました.

こんな感じですので、あとは適当に文字列をダミー変数に置き換えたり、日付をdate関数で整えたりしていけばよさそうです.
さて、これを複数のシートに跨ったデータとして、ループで処理してすべてマージする、という方法を採れば一人複数行、縦持ちデータが完成します.
import excel "format_repeat.xlsx", describe
return list
clear
forvalues i=1/`r(N_worksheet)' {
import excel "format_repeat.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_`i')') allstring
drop A
rename B variable
replace variable = "回数" in 1
replace variable = "日付" in 2
replace variable = "投薬A" in 3
replace variable = "投薬B" in 4
replace variable = "投薬C" in 5
replace variable = "投薬D" in 6
replace variable = "投薬E" in 7
replace variable = "Stage" in 8
sxpose2, firstnames clear
gen id = "dummy`i'"
save tempfile_`i'.dta, replace /* 中間データとしていったん保存 */
clear
}
import excel "format_repeat.xlsx", describe
return list
clear
use tempfile_1.dta, clear
forvalues i = 2/`r(N_worksheet)' {
append using tempfile_`i', force
}
order idこれで以下のような表が出来上がりました.これならば解析にうまく使えそうですね.
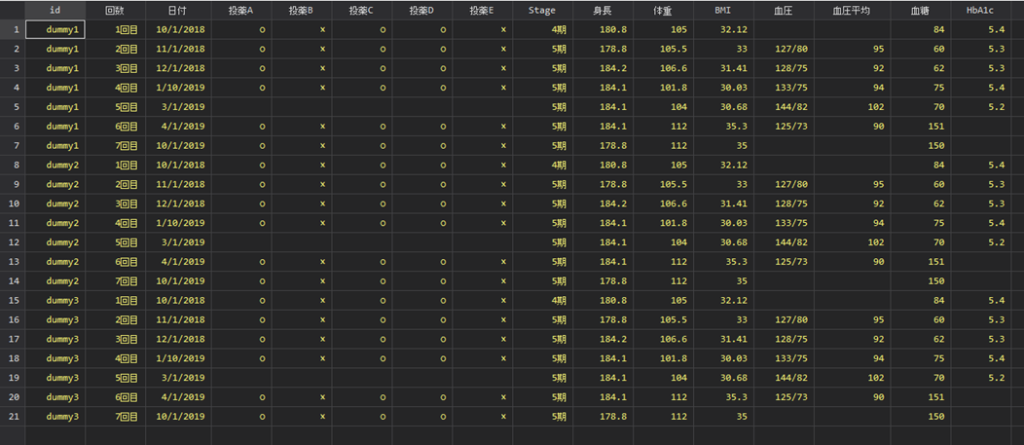


コメント