
今回はカプランマイヤーを綺麗に描くためのポイントを書いてみます.
以下のエレメントを順番に加えたときにどんなグラフになるかを見てみましょう.
- Figure legendの位置を調節し、表記を自分好みにする
- at-risk tableを追加する
- P値をグラフの中に組み込む
1.Figure legendの調整
まずはカプランマイヤー曲線がデフォルトでどのように表示されるのかを確認しましょう.Stata自前のデータセットを使わせていただきます.
webuse drug2, clear
sts graph, by(drug)
sts test drug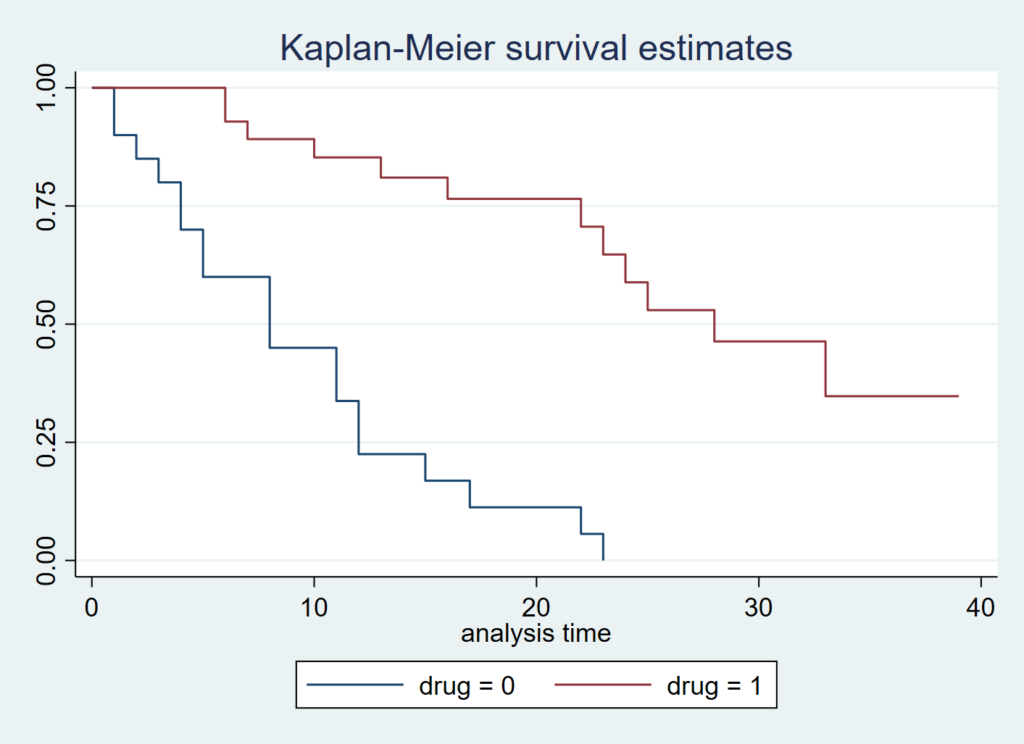
Legendの表記や位置が気にくわないし、検定結果もどうせなら中に入れてしまいたい! と思えてきます.
そこでまずはLegendから修正してみます.
sts graph, by(drug) legend(position(1) ring(0) col(1))
legend optionの中の positionは時計回りの位置関係、ringはグラフエリア内か外か、col()は何列にするかをそれぞれ意味します.
position(1)とすれば時計の1時の位置に配置されますよ、ということになり、ring(0)とすればグラフエリア内になりますよ、となり、col(1)とすれば縦一列に並べます、ということになります.
drug = 0はプラセボ、drug = 1は実薬群らしいのですが、この表記を整える方法として、2つ知っておくとよいでしょう.
1) sts graph, by(drug) legend(order(2 “Drug” 1 “Placebo”) position(1) ring(0) col(1))
2) sts graph, by(drug) legend(label(1 Placebo) label(2 Drug) position(1) ring(0) col(1)) 1)を推奨します.理由は簡単で、実薬群が上にくるほうが感覚的にしっくりくるからです.2)の方法も汎用性が高いので覚えておきましょう.
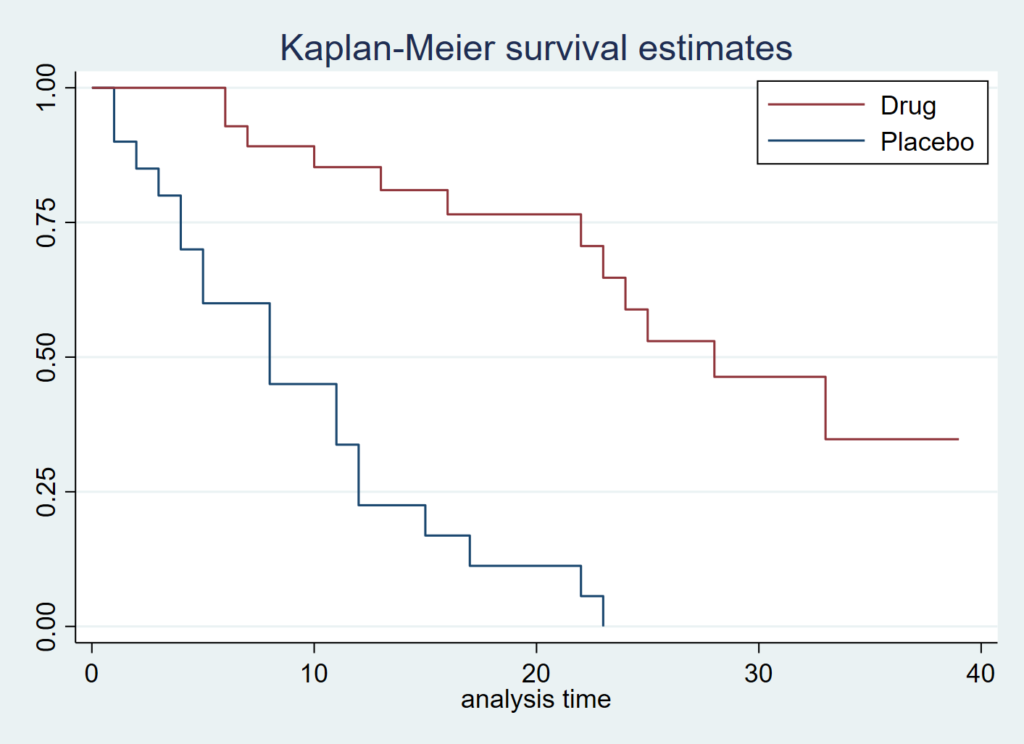
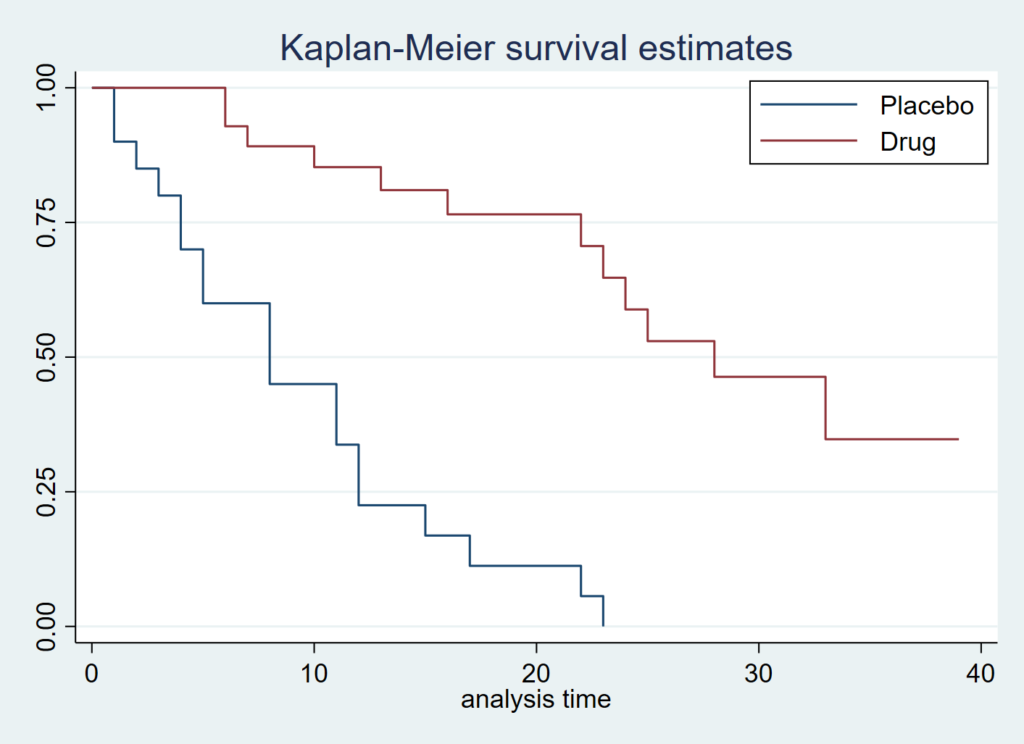
2.at-risk table
カプランマイヤーの下にリスクテーブルをつけたり、打ち切りに対して「ひげ」をつけたりしておくことができます.
sts graph, by(drug) legend(order(2 "Drug" 1 "Placebo") position(1) ring(0) col(1)) risktab 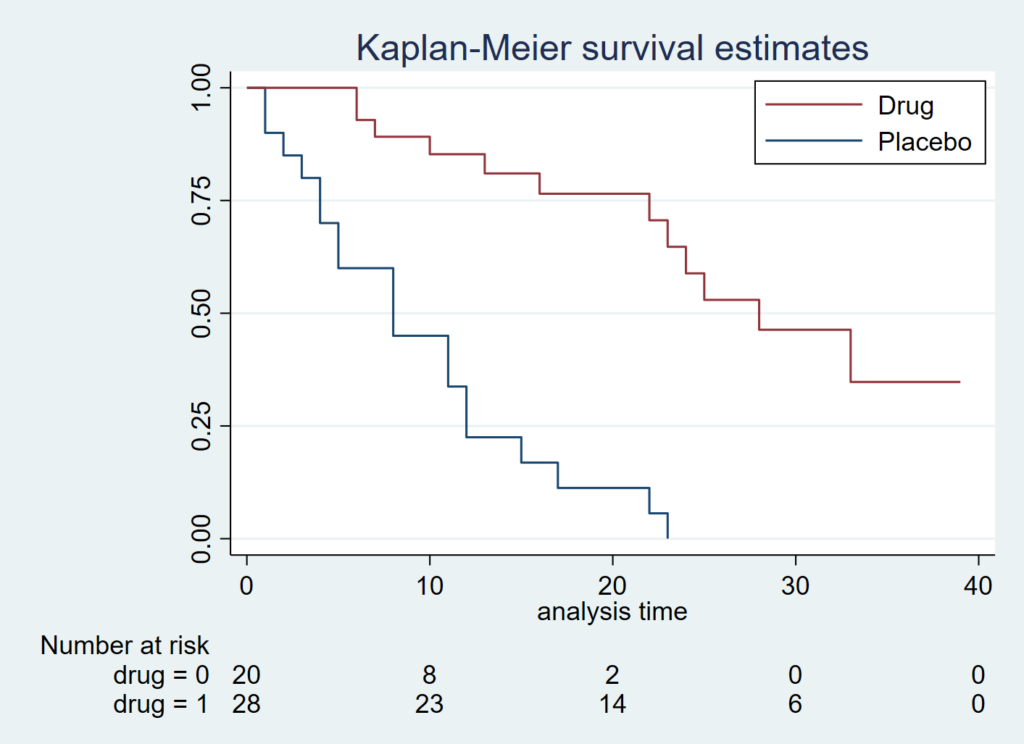
sts graph, by(drug) legend(order(2 "Drug" 1 "Placebo") position(1) ring(0) col(1))risktab( , title("") order(2 "Drug" 1 "Placebo"))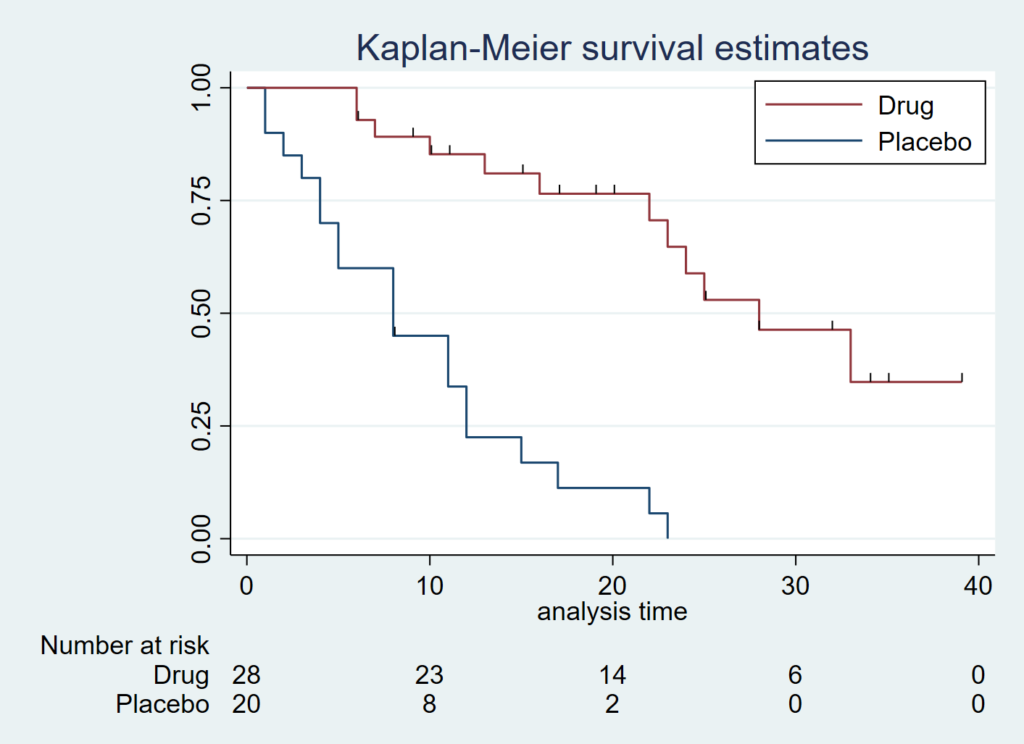
3.P 値をグラフ中に組み込む
これをするにはまずP値を取り出すことから始めなければなりません.残念ながらLog-rank検定のコードから直接P値を取り出すことはできず、計算しなければいけません.
.sts test
各コマンドのオンラインヘルプの一番下には、どんなスカラー値がとれるのかをまとめてくれています.そこで見てみると、
Scalars
r(df) degrees of freedom
r(df_tr) degrees of freedom, trend test
r(chi2) chi-squared
r(chi2_tr) chi-squared, trend test
つまりカイ二乗分布に基づいてP値を計算することになります.以前の記事にも記載しましたが、カイ二乗分布に基づいたP値の計算は、
1 – chi2(自由度, カイ二乗値)
で与えられるので、
1 – chi2(r(df), r(chi2))
となります.最終的には以下のようなプログラムになります.
sts test drug
local P: disp %4.3f 1 – chi2(r(df), r(chi2))
sts graph, by(drug) legend(order(2 "Drug" 1 "Placebo") position(1) ring(0) col(1))risktab( , title("") order(2 "Drug" 1 "Placebo")) censor(s) text(0.15 30 "Log-rank test" " " "P=`P'") xtitle(Observation Period)
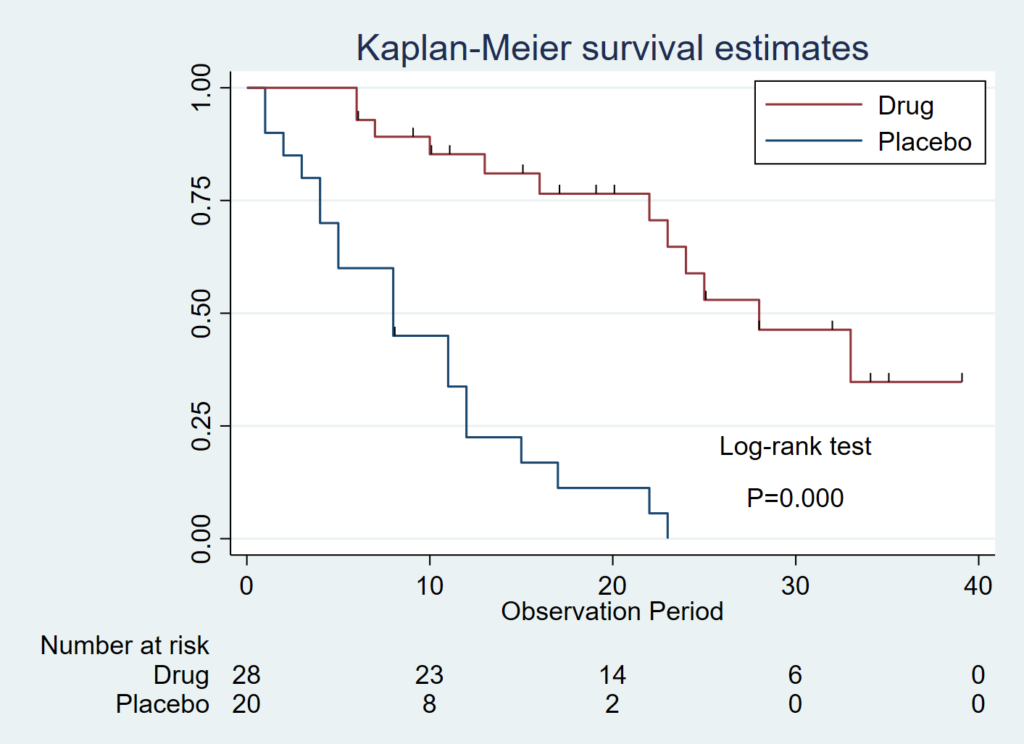
text(y軸の値 x軸の値 載せたい値)
4.まとめ
Legendを自分好みにし、at-risk tableを付け、Log-rank検定の結果を組み込んだカプランマイヤーの描き方をまとめました.
誰かの参考になれば幸いです.

コメント