
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、Case-control studyの1つでincidence dense samplingとかriskset samplingとか言われる方法でコホート内でコントロールを時の流れをそろえて抽出してくる”nested case-control”を以前ご紹介しました.それをStataで実装するコマンドがあり、”sttocc“といいますが、その使い方をご紹介します.
この方法を使って大学院生の時に行った研究の論文が長らく塩漬けになっていたのですが、ようやくアクセプトされましたので、その内容も少しご紹介しつつ解説させていただきます.
1.Nested case-controlデザインがなぜコホート研究に匹敵するのか?
これは以前の記載の復習になります.
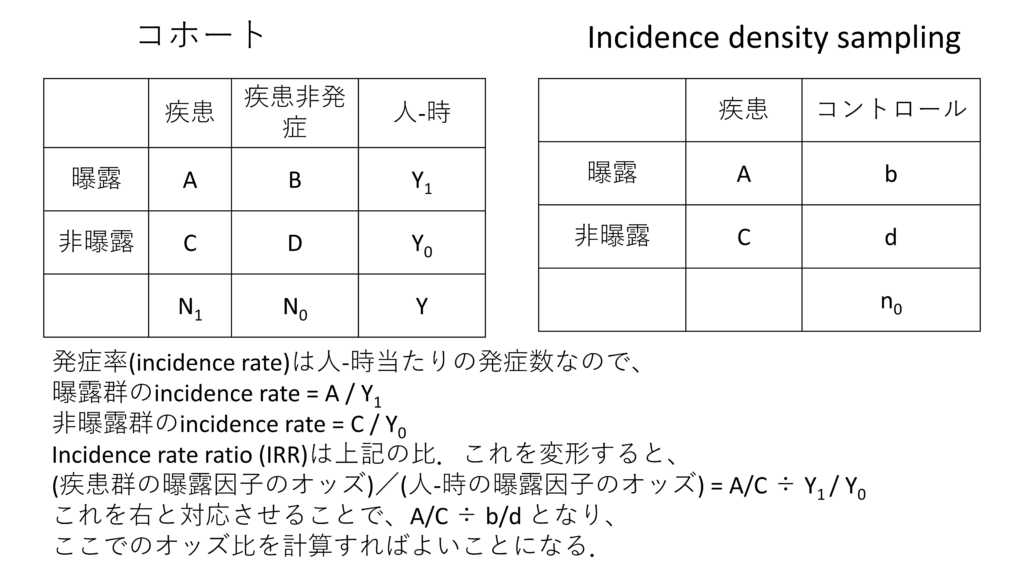
Caseが発生したタイミングで、その時点ではまだ発症していない人たちからランダムにControlを抽出してくる、という方法です.結果はコホート研究で算出できるincidence rateの比と同じように解釈できるので、完全なコホートとほぼ同等に扱えます.
どうしてincidence rate ratioとして結果が解釈できるのか、ということなのですが、Controlとして抽出してきた人達は、すでに人-時のうちの”時”の部分はサンプリングしてくるときにCaseと同じになるので純粋に人数比だけで済む、という考え方です.下の図が解説になります.
2.3つのステップ
このコマンドを走らせるためには3つのステップを踏めばよいです.超簡単.
- 生存時間分析を実行する(あたかもコホート研究!)
- seedを設定する(乱数を発生させる規則を決めるため.疑似ランダム)
- “sttocc”でNested case-controlを設定
1.生存時間分析を実行する
Sample dataを使いながら解説していきます.
webuse diet, clear
stset dox, failure(fail) enter(time doe) id(id) origin(time dob) scale(365.25)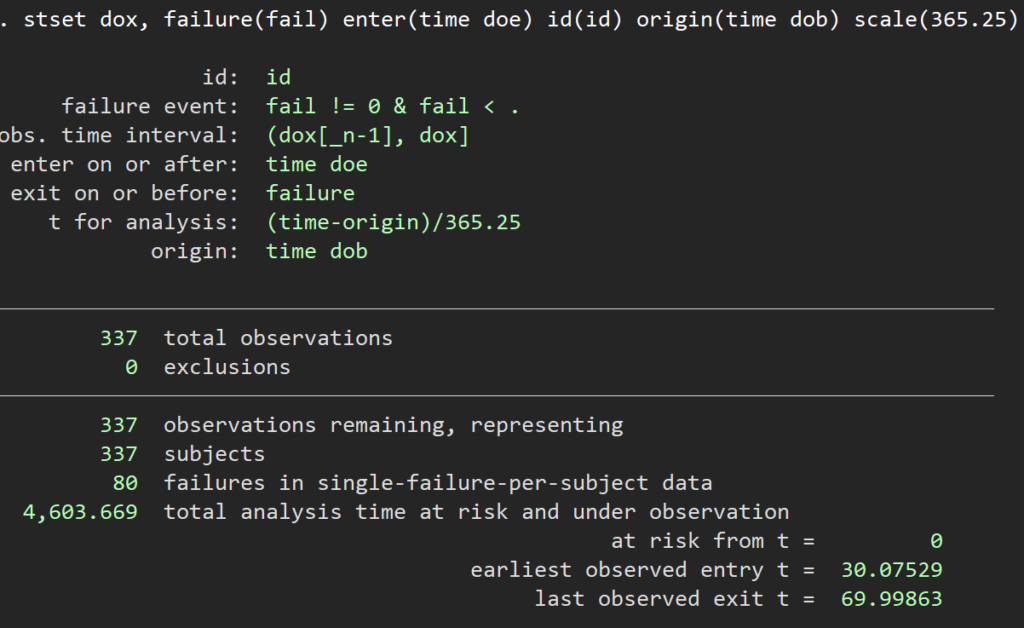
ここまでは通常の生存時間分析と何ら変わりないですね.
2.Seedを設定する
このあとのsttoccでは乱数を発生させる必要があるため、seedを設定します.何かのrandom関数を含むようなプログラムを走らせる前に設定します.
webuse diet, clear
stset dox, failure(fail) enter(time doe) id(id) origin(time dob) scale(365.25)
set seed 91234563.sttoccを走らせる
ここで真打登場です.このコマンドでは、次のことを決める必要があります.
- マッチングの有無:年齢、性別などのマッチングをすることが通常です
- 1:nの設定:4以上にしてもあまり検出力は変わらないとされていますが、1~4までならなるべく多いほうがよいです
set seed 9123456
sttocc, match(job) n(5)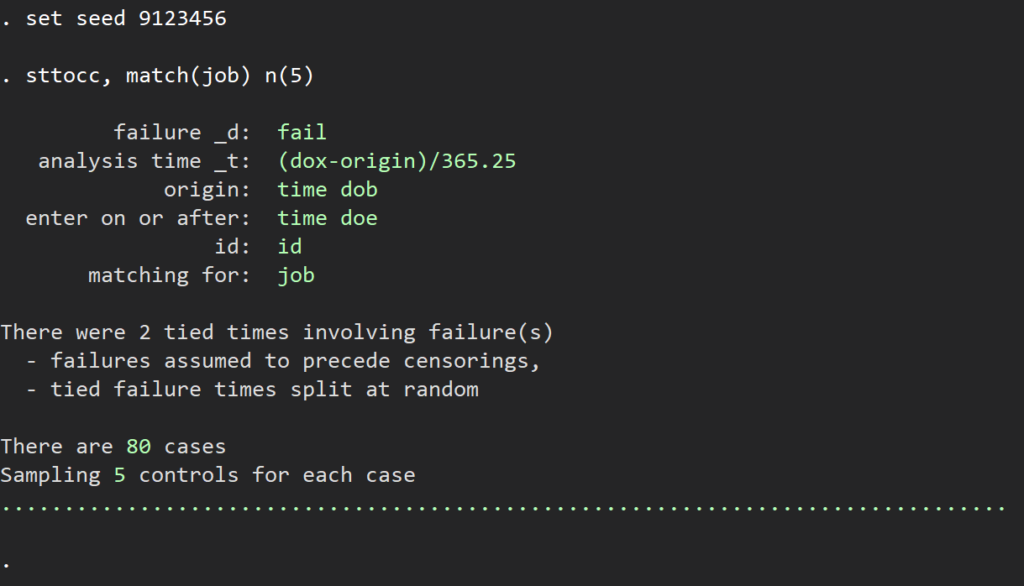
ここで症例80例に対し、1:5でマッチングしているので、合計は480になります.このプログラムでは、同じ症例が繰り返し使われます.
4.条件付きロジスティック回帰をあてはめる
さて、以上で1:5のcase-controlができましたので、次はそれをconditional logistic regressionにあてはめると、出力されたORがHRのように解釈可能、ということになります.
clogit _case energy height weight hienergy, group(_set) or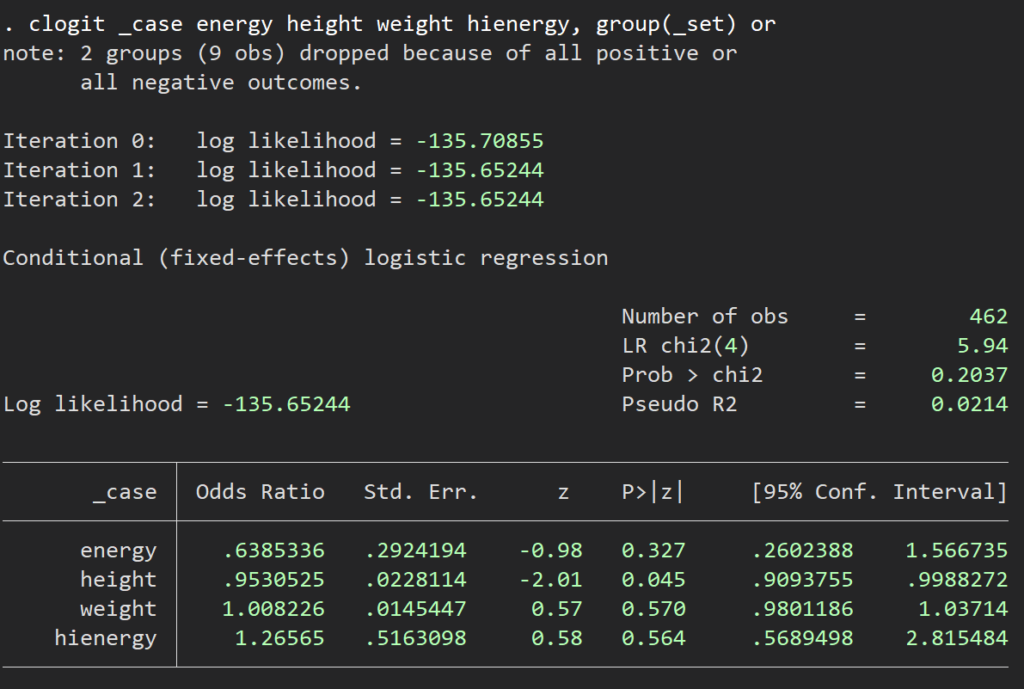
これによりアウトカムは身長が高いほど有意に発生しにくい、ということになりました.
5.具体的な使用例ご紹介
またも自分の論文を紹介する、という何とも気恥ずかしい流れになってしまいました.かれこれ5年くらい前の自分がStataいじり始めたころ、そして疫学の勉強も始めたばかりの頃に病院のデータを一生懸命に抽出してやった手作りの研究です.
ICUに入室した人の血清ナトリウム上昇に、ステロイドの投与が関与しているのではないか、という臨床的な実感があったことがモチベーションでした.高ナトリウム血症の症例を100例あまり集めるのにだいたい3年くらいのデータがいるだろうということでおよそ1700名分のデータを集めることになりました.
しかし、カルテを一枚一枚めくるという作業が許容されるのはせいぜい数百例が限度です.何とか症例数を減らせないか、という工夫の産物がこの研究デザインでした.
そして輸液、すべての投与薬剤、その他ICU入室後のすべての経過を記録して研究を実施しました.結果として250名程度のデータ収集で済んだこと、またICU入室後の状況も反映させることができたこと、重要な交絡因子の影響を考慮に入れながら解析ができました.
結果としては、AKIや浸透圧利尿薬の使用とは独立して、中等量以上のステロイド投与(パルス含む)がICU入室中のナトリウム上昇に関連することが証明されました.

ICUを出てからの発症をdetectできていないこと、またステロイドの曝露は発症するよりも以前のものに限定したことなどの条件はもちろんつけてデータを抽出しています.
病態の仮説として、異化の亢進による尿素産生増加からurea diuresisという浸透圧利尿の一種が生じているのではないか、ということがあります.
また、量反応関係としてはパルスの有無よりもステロイド投与期間のほうが影響が大きいということから、ステロイドによるsodium retentionも関係しているかもしれません.
輸液によるナトリウム負荷は今回、有意な関連を持ちませんでした.
輸液量や投与薬剤、既往歴といった情報を集めるのに、今だったら電子カルテからの自動抽出を何とか工夫するかと思いますが、その当時はそんな発想はなく、ひたすら夜なべしてカルテ情報をfilemakerに転記していました.
「もういや…」とか何度も思いましたけど、とにかくpaperにしたい!という気持ちが強くて気力を振り絞っていました.
紹介した研究は1:1のマッチングをしました.本当は元気があれば1:4とか頑張りたかったのですが、そうなると600症例もやらねばならず、断念.現実的な症例数で勝負せざるを得ませんでした.
まとめ
sttoccコマンドを使ったNested case-control研究のやり方をご紹介しました.症例数を減らしながらコホート研究と同じような結論を得られる研究デザインとして有望だと思います.
特殊な検査を要する研究、特殊な因子への曝露を調査する研究など用途は様々です.
sttoccはマッチングする変数を選ぶことはできますが、例えば年齢の幅を持たせたり、といったことはできません.その場合には変数を新たに作って年齢をある程度丸めたりすることが必要です.もしくは自力でNested case-controlができるようなプログラムを作ることも可能です.
自作のプログラムがあるのですが、さすがにこれはどこもサポートしていないので紹介するのは憚られますね…。


コメント