
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、本日の記事は、横持ちのデータセットからある規則に則って値を取り出す方法について考えてみました.
1.データセットの概要
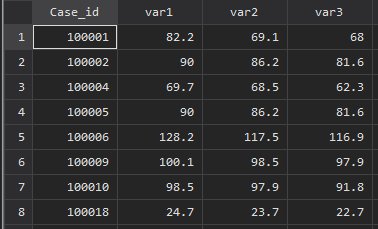
こちらのサンプルデータを使って解説します.
1人の患者さんが合計10回同じ検査を受けている場合を想定しています.

この横に連なるデータの中でそれぞれの個人から上位3つずつのデータを取り出す方法を考えてみたいと思います.
2.具体的なプログラムの一例
まずは横持ちのデータを縦持ちのデータに変換します.使うコマンドはreshape longです.
reshapeというコマンドは縦持ち→横持ち、横持ち→縦持ちにデータを変換するときに使用するコマンドです.縦持ち→横持ちにするためにはreshape wide, 横持ち→縦持ちにするためにはreshape longと目的となるデータ形式をreshapeコマンドの直後に書くのがポイントです.
そして必ずi変数(IDなど個人を識別するための変数)と、j変数(繰り返し回数を表す変数)をオプションで指定する必要があります.iはindividual、jはjikan(時間)と覚えるとわかりやすいですね、日本語だけど(笑)
さて、今回は繰り返しのj変数が最初は存在しないので適当に_tなどと任意で指定します.
import excel labodata_wide, sheet("Sheet1") firstrow clear
reshape long var, i(Case_id) j(_t) /* 縦持ちにするため、j変数を新たに作成 */これによって横に並んでいたデータセットが縦に並びます.
元に戻すにはreshape wideと打ち込むだけでできてしまいます.簡単ですね.
注意すべきなのは、i変数とj変数が1つずつあれば決まるようなデータ(unique)でなければ受け入れてくれません.試しに一行同じIDで同じ繰り返し回数の変数を入れてしまいましょう.
replace Case_id = 100018 in 81
replace _t = 10 in 81
replace var = 0 in 81
reshape wideすると、以下のような警告がでてしまいます.
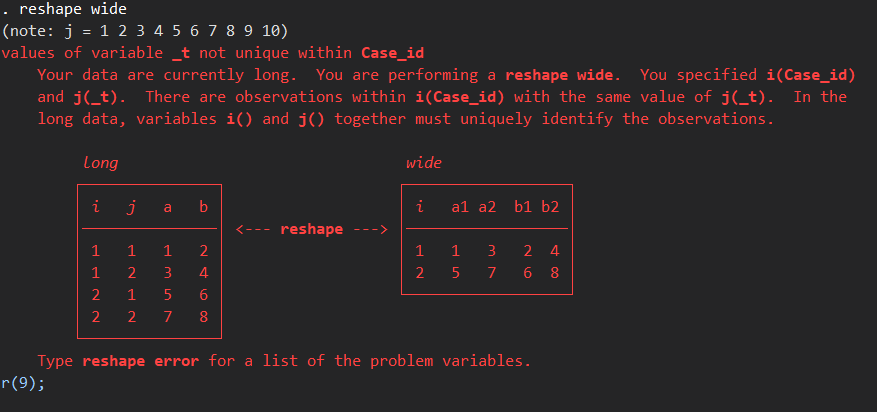
勝手に_tが10である行を追加したことにより、id: 100018さんの10回目の検査結果が複数存在してしまうためにuniqueでなくなってしまいました.なので、複数あるレコードはどちらかにしなければなりません.
さて、元通りのデータにもう一度し直して、いよいよ上位3つを取り出す方法を考えてみましょう.
IDごとにグループを分けてその中で大きい順に番号をつけるとよいです.
import excel labodata_wide, sheet("Sheet1") firstrow clear
reshape long var, i(Case_id) j(_t)
reshape wide
gsort Case_id -var
bysort Case_id: generate n = _nすると以下のようになります.
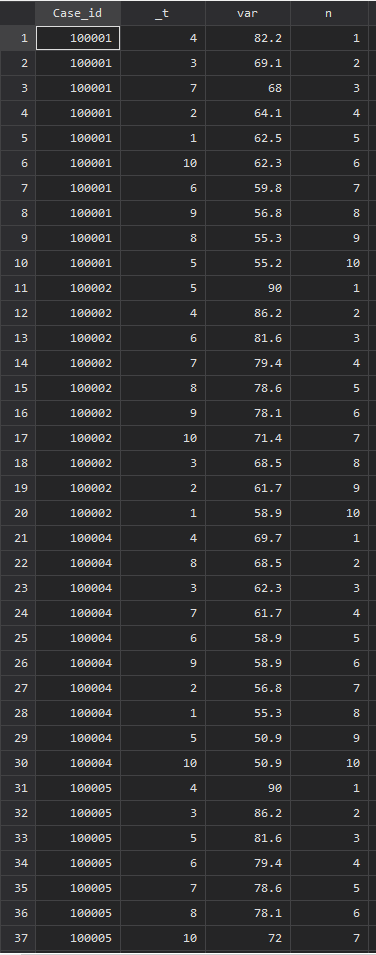
大きい順に並んでいることがわかりますね.これで上位何位まででも並べることができますので、nが4以上のものを削除します.(drop if n>3)
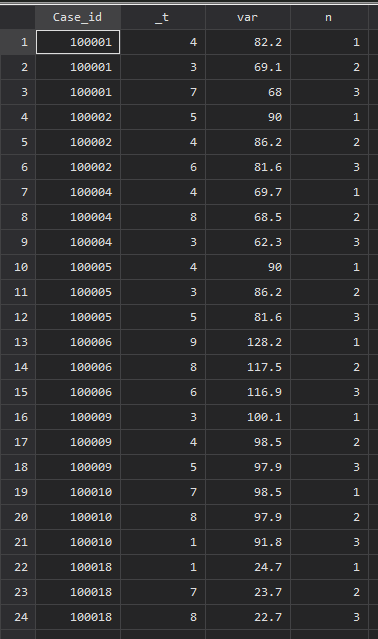
これを横に並べたければもう一度reshapeします.このとき変数をもう一度指定しますが、nに合わせることにして、_tは消してしまいましょう.
drop _t
reshape wide var, i(Case_id) j(n)そうすると上位3つのみがでてきます.
まとめ
データクリーニングのプロセスは1つの正解しかないというわけではありません.少しずついろいろと試していって、自在に操れるようになると非常に便利です.
ぜひご自分でプログラムを組んでみてください.


コメント