
ひさしぶりの更新となりました。皆様お元気でしょうか?世間はコロナウイルス一色ですが、在宅で仕事する人も増えてきているでしょうか。
さて、今日はデータマネージメントを学ぶためのStata pressの書籍とWebサイトを1つ紹介させてください.
Data Management Using Stata: A Practical Handbookという書籍です.
さらにStata pressのWebsiteには書籍で説明されているデータセットやDofileなどがsupport materialsから無料でダウンロードできます. このリンク先からzip fileをダウンロードするか、Stataがネットにつながる場合には、以下のコードを打つことで現在のworking directoryにデータが格納されます.
### 本の中で解説されているデータセット
net from http://www.stata-press.com/data/dmus/
net get dmus1
net get dmus2このように入れると、フォルダ内にデータセットやDofileが溢れかえる状態にないります.(114個のファイルが追加されます)
詳しくは書籍を購入していろいろいじってみると良いと思いますが、個人的にはこの書籍のdata cleaningの部分とcreating variablesの部分がとても勉強になりました.
個人的に有用と思われたコマンドを紹介していきます.
1.describe -データセットの全体像の把握-
これはデータセットを展開したあとに一番最初に使うべきコマンドの1つで、 データセットの名称、observation数、変数の種類、データの大きさなどのあとに一つ一つの変数に関する概要がリストアップされます.データセットの定義書を作成する際にも役立つでしょう.表の構成としては、
| variable name | 変数名 |
| storage type | データのタイプ |
| display format | 表示形式(桁数など) |
| value label | 値ラベル(選択肢の名称) |
| variable label | 変数ラベル(図表や結果に表示される) |
これとsummarizeコマンドで欠損の程度や大まかな分布を一覧で確認できるので、データセットをStataで読み込んだら最初にこれらのコードでデータの大まかな構造をつかむとよいです.
ちなみに、summarizeコマンドは、レコード数、平均、標準偏差、最大値、最小値が一覧で出すことができます.detailのオプションを使えばその他の代表値を出すことができます。
sysuse auto, clear
describe
sum
sum, detail

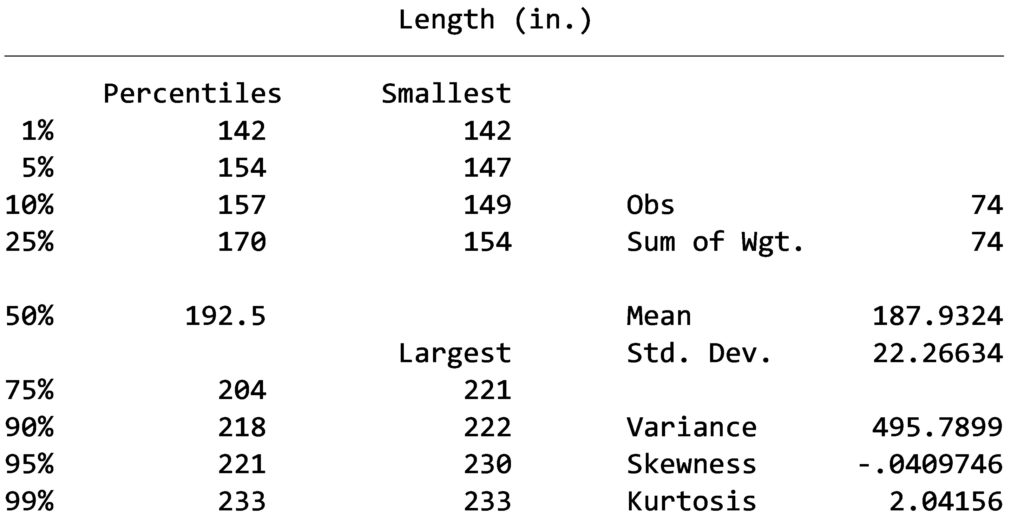
sum length, detail
2.duplicate ー重複のチェックー
このコマンドは重複データに関していろいろな事ができます.
1) duplicates report [varlist] [if] [in]
重複を報告する
2) duplicates examples [varlist] [if] [in] [, options]
重複の1例を挙げる
3) duplicates list [varlist] [if] [in] [, options]
すべての重複をリストアップする
4) duplicates tag [varlist] [if] [in] , generate(newvar)
重複したものにフラグを立てる(newvarがフラグ)
5) duplicates drop [if] [in]
duplicates drop varlist [if] [in] , force
重複削除3.misstable ー欠損値を確認するー
webuse studentsurvey, clear
misstable summarize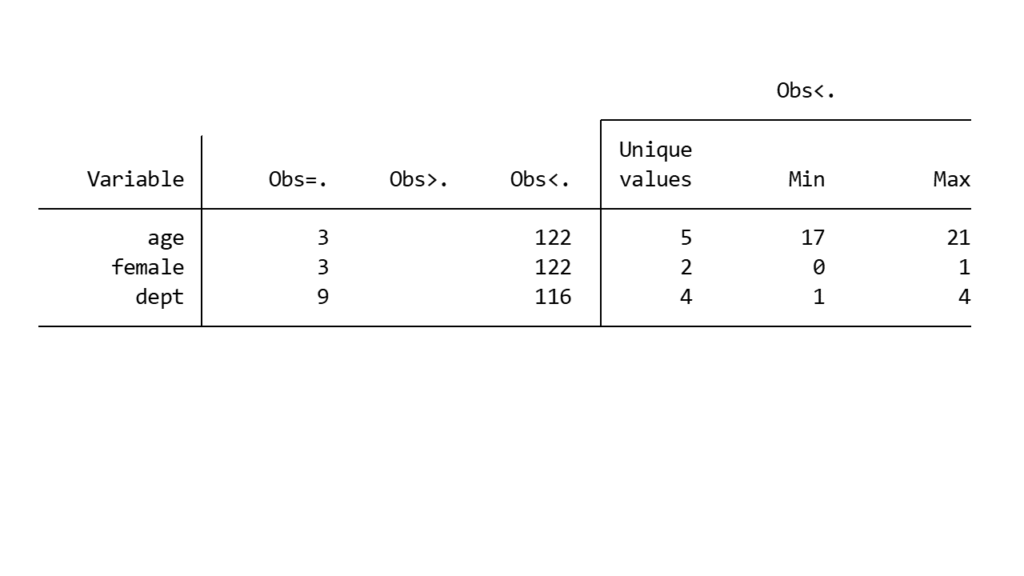
欠損値がどれだけあるのかを知ることができます.すべてのレコードが欠損なく存在している場合、この表に現れませんので、オプションのallをつけるとよいでしょう.
欠損の仕方によってはリカバリが可能な場合がありますよね.BMIはないけど身長と体重はある、とか、トランスフェリン飽和度はないけど鉄と総鉄結合能はある、みたいな状況です.こういう状況であれば計算可能ですので、欠損のパターンも重要です.
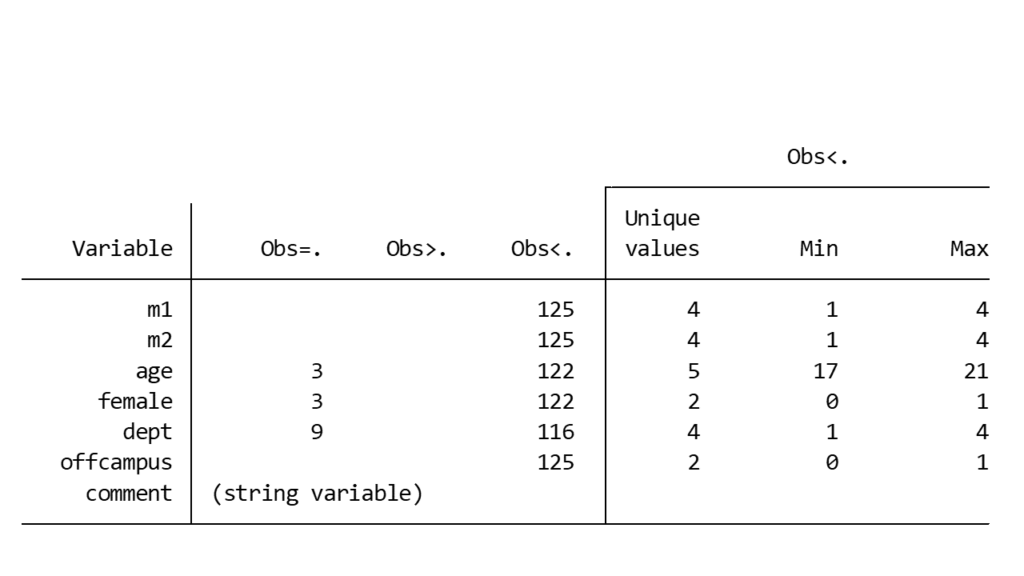
webuse studentsurvey, clear
misstable pattern
こういった表し方も役立つときがありますので押さえておくとよいでしょう.ちなみに多重補完の時にもこのmisstable summarize, allとかmisstable patternはよく使います.
4.codebook -定義書・data dictionaryの作成に便利-
codebookコマンドはそれぞれの変数のタイプ、最大最小値、欠損値、unique valuesなどを示すのに便利ですので、data dictionaryの作成に役立つと思われます.
webuse studentsurvey, clear
codebook ageこれで指定した変数の詳細が出力されます.単純にcodebookと入れるとすべての変数が出力されます.logに残す上でもこれを出力しておくとよいでしょう.
5.データクリーニングの極意 ーまとめに代えてー
データの解析を行う際には、まずそのデータが正しいものか、解析に耐えるものかどうかをきちんと確かめることが重要です.
まずデータセットをStataで開いたら真っ先にデータの全体像を確認します.そのときに使えるのがdescribe, summarizeとなります.
次に重複データがないかをみるのにduplicateコマンドを使います.
そのあとはデータ一つ一つの分布、割合、ロジカルチェック(誕生日より研究開始日が過去、研究開始日より前にイベントが発生しているなどがないかを確認)を一通り行っていきます.
データがきちんと整っているかを確認するのは基本中の基本です.ここをおろそかにしないことが重要だと思います.

コメント