
さて、今日はBaseline characteristicsを要約した表(いわゆる”Table 1”)をあっという間に自動生成してしまう、便利なコマンドである”.table1_mc”をご紹介します.
このコマンドを作成したのは、オーストラリア人のPhilip Clayton先生で、アデレード医大の先生です.ANZDATAというオーストラリア・ニュージーランドの透析・腎移植レジストリーの疫学の偉い人のようです.オーストラリアに足を向けて寝られませんね.(北枕にもならないで済む?)
さて、内容を解説しますが、例によってコマンドのインストールをする事も含めて難しいことは一切ありません.解説もシンプルで読みやすいです.
1.このコマンドでできること
- グループごとの要約値を、変数の種類を指定し、桁数を指定して表示
- グループはいくつあっても対応
- 各変数の要約値をエクセルで出力
- 同様にワードに出力(脚注もつけられる)
2.コマンドのインストール
.help table1_mc あるいはfindit table1_mcなどと入力すると、”table1_mc”というパッケージが候補にでてきますので、それを選択します.そうすると次の様な画面がでてきますので、”click here to install”をクリックするとado-fileが手に入ります.
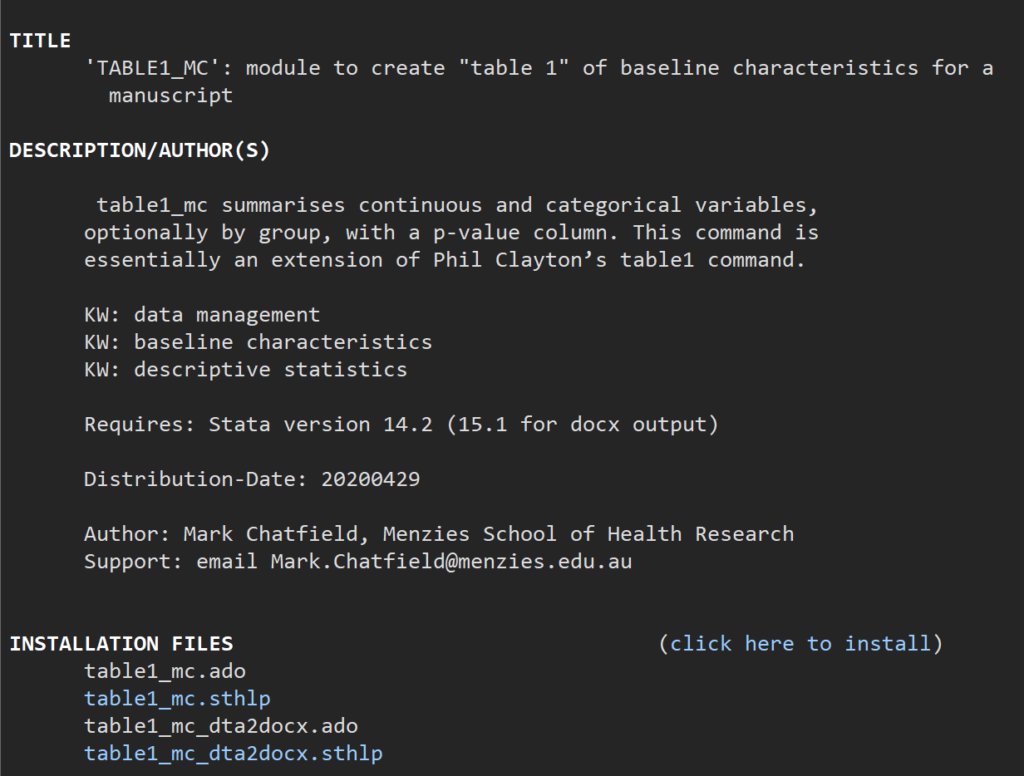
ヘルプ画面を見ていただくとわかりやすい説明があります.詳しくはそちらを見ていただければいいですが、いくつか実行する上で注意すべきことを中心にまとめていきたいと思います.
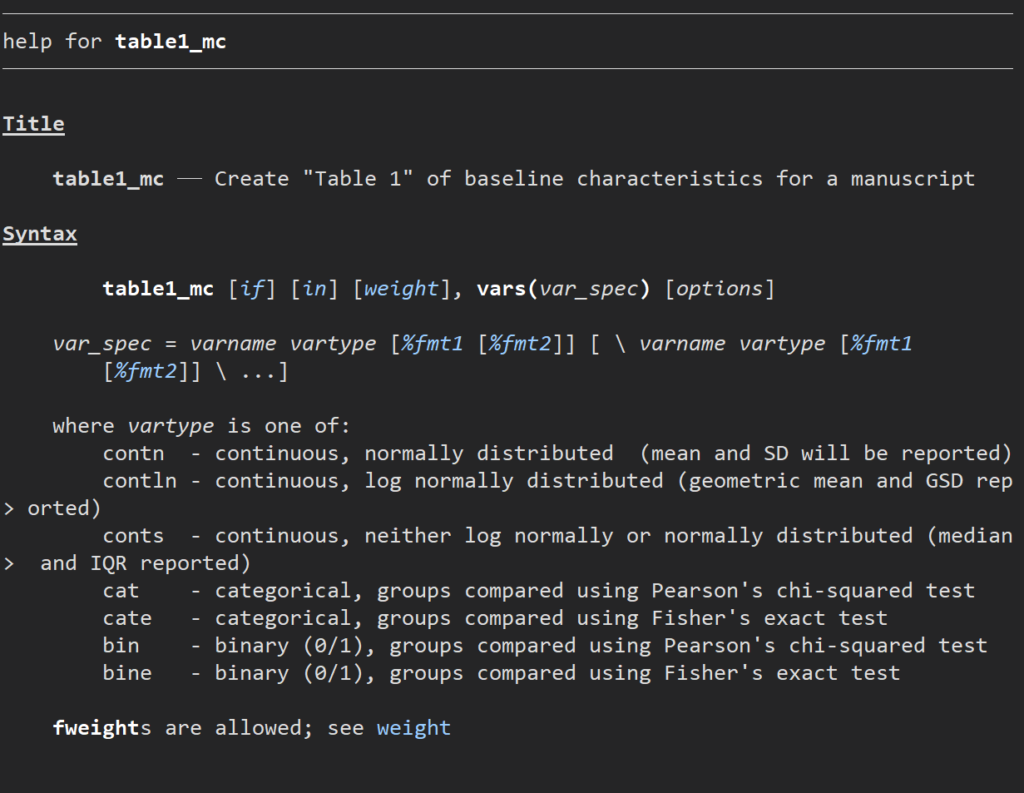
3.基本的な文法
次のようなsyntaxに則って書き出します.見やすさから、do-fileに展開しながら書いていくほうがやりやすいです.
.table1_mc, vars(変数名1 変数タイプ [表示桁数] \ 変数名2 変数タイプ [表示桁数] \ …)
これも#delimitで括りながら記載していくほうが複数の変数を並べていくのに見やすいと思います.
sysuse auto, clear
generate much_headroom = (headroom>3)
table1_mc, by(foreign) vars(price conts %5.0f \ price contln %4.2f \ weight contn %5.0f \ rep78 cate \ much_headroom bine)とやるよりも、
#delimit;
sysuse auto, clear
;
generate much_headroom = (headroom>3)
;
table1_mc, by(foreign)
vars(price conts %5.0f \
price contln %4.2f \
weight contn %5.0f \
rep78 cate \
much_headroom bine)
;
#delimit crこちらのほうが変数の変形がわかりやすいように思います.あとは好みの問題でしょうか.
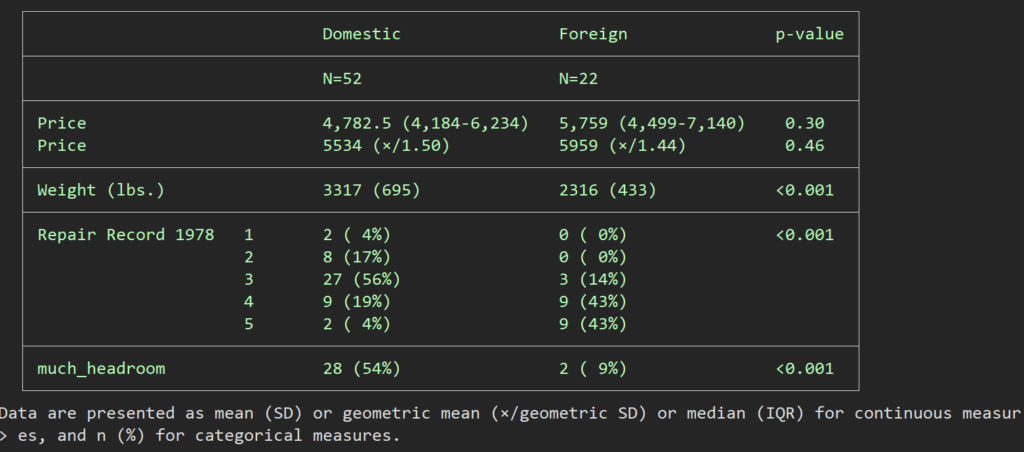
これをエクセルに出力したければ、”saving()”のオプションを追加すればよいです.()の中はセーブするためのファイルの名前を指定しますが、どのディレクトリに保存するかも指定できます.(何も書かなければ現在のworking directoryに格納されます.)
#delimit;
sysuse auto, clear
;
generate much_headroom = (headroom>3)
;
table1_mc, by(foreign)
vars(price conts %5.0f \
price contln %4.2f \
weight contn %5.0f \
rep78 cate \
much_headroom bine)
saving("N:\example Table 1.xlsx", replace) clear
;
#delimit cr4.変数の種類や桁数を指定する
変数名の直後に変数の種類を指定します.
- contn – 正規分布する連続変数 (normally distributed) (mean と SD が報告されます)
- contln – 対数変換で正規分布する連続変数 (geometric mean と GSD が報告されます)
- conts – ノンパラメトリックな連続変数 (median と IQR が報告されます)
- bin – 2値変数 (0/1), (Pearson’s chi-squared testの結果がつきます)
- bine – 2値変数 (0/1), (Fisher’s exact testの結果がつきます)
- cat – カテゴリー変数 (複数カテゴリに対応.Pearson’s chi-squared test)
- cate – カテゴリー変数 (複数カテゴリに対応.Fisher’s exact test)
桁数の指定は、%4.0fなどのように表記しますが、前の数が全体の桁数の上限、コンマの後の数が小数点以下の桁数を表します.
変数の直後に入れると一つ一つを指定しますが、format()オプションを使えばvars() の後にまとめて指定することもできます.(f()と省略形でも可)
#delimit;
sysuse auto, clear
;
generate much_headroom = (headroom>3)
;
table1_mc, by(foreign)
vars(price conts \
price contln %4.2f \
weight contn \
rep78 cate \
much_headroom bine)
format(%5.0f)
;
#delimit cr上記のプログラムでは、price contlnのときだけ小数点第2位まで表記することにしています.
5.さまざまなオプション表示形式
その他、便利なオプションを紹介します.
- by(varname) :varname(グループ)ごとの要約値を返します.(i) 名義変数でも (ii) 数値変数でもOKですが、マイナスの値を含まない整数である必要があります.ラベルが貼ってあってもなくてもOKですが、あった方がきれいに表示されますので、値ラベルをつけておくことをオススメします.
- total(before|after) :トータルの集計値を入れるかを各グループごとの集計値より前か後ろか指定するオプションです。これはもっぱらbeforeでしょうか.
- onecol:複数のカテゴリーを持つカテゴリー変数を1つのカラムで表示するかどうかを決めるオプションです.
- missing: 欠測値を省かずに集計するものです.(二値変数以外)
- test: 検定の種類を記載します.
- pairwise123: ペアワイズ比較を最初の3グループで行うものです.多重検定に対する調整は行われません.(あまり使わないかもしれません)
by(varname)とtotal(before)は必須でしょう.場合によってはmissingを入れてもよいと思います.
続いてセルの中の表示形式のオプションです.
- format(%fmt): すべての連続変数に対するデフォルトの桁数設定です.
- percformat(%fmt): カテゴリー変数や二値変数のデフォルトのパーセンテージ表示の桁数設定です.
- nformat(%fmt): サンプル数などの表示形式です.デフォルトはnformat(%12.0fc)となっています.
- iqrmiddle(“string”): 四分位範囲を表示する形式を指定できます.デフォルトは median (Q1-Q3) ですが、iqrmiddle(“,”) とすれば median (Q1, Q3) のように表示できます.
- sdleft(“string”): mean (SD)と表示されるのがデフォルトですが、sdleft(“±”) とすれば mean±sd と表示できます.
- sdright(“string”): 上記とセットで用いますが、sdright(“”) と入れることで、右側の”)”をなくすことができます.
- gsdleft(“string”): geometric meanを表示するときに記載方法の自由度を持たせます.デフォルトでは (×/geometric_SD)
- gsdright(“string”): これも上記と組み合わせましょう.gsdright(“”)
- percsign(“string”): %の表示がデフォルトとなっているので、それを消したい場合には percsign(“”) とします.
- nospacelowpercent: %の左側がデフォルトでは空いてしまうので、それを調整します.つけておいた方がよいでしょう.
- percent: n(%)がデフォルトですが、 % のみを表示する場合につけるオプションです.
- percent_n: n(%)がデフォルトですが、 % (n) と表示させます.あまり使わないでしょう.
- slashN: 分母を同時に表示させる方法で、 n/N となります.
- catrowperc: 3つ以上のカテゴリー変数において、行の中でのパーセンテージを表示します.当然ながらデフォルトでは列間でのパーセンテージなわけですが.
- pdp(#):P値を表示させる桁数の上限を設定します.デフォルトは3桁です.pdp(3)
さらに、結果をWordにエクスポートする場合には、clearオプションする必要があります.(63行までしかエクスポートできない、とはじかれてしまいます.)
6.Wordにエクスポートする
ここまで来ただけで目から鱗ものなのですが、さらに結果をワードに出力できてしまう、という点がさらに恐ろしいところでしょう.
“table1_mc_dta2docx” というコマンドを使います.
まず、指定のディレクトリの中にWordのTableを入れるためのdocument fileを作ります.これはいわば入れ物であり、名前が付いていればOKです.
基本的なsyntaxは、
.table1_mc_dta2docx using filename [, options]
ですので、自分で勝手にファイル名をつけておいた「入れ物」の名前をfilenameとして書いておくだけでよいです.
ここで押さえておきたいオプションは次の通りです.
- tablenumber(string): Table numberを指定します.tablenumber(“Table 1.”) のように記入すれば、Wordに出力されるときに “Table 1.” が左上に出現します.しかも太字です.
- tabletitle(string): ここにはTableのタイトルを記入しましょう.tabletitle(“Baseline characteristics by group.”) のような感じです.これは太字にはなりません.上記のTable numberの直後に書かれます.
- footnote(string):これは脚注を入れるのですが、集計のために使われた検定方法などについてはデフォルトで入りますので、主に略語に関する記載でよいです.
- replace:古いものと交換します.最初の表だけこのオプションにして、2つ目以降はappendでよいでしょう.
- append:同じファイルに上書きせず、続きから書き出してくれます.
7.最後に
Table 1を書くときにもう一つの面倒な作業が、変数の正しい表示名を書き出すことなのですが、これはlabelの通りにはき出してくれます.故にラベルを正しく付与すれば自ずと欲しい結果が表示される、ということになります.
ただしここで注意したいのは、べき乗数を表示するHTMLとしてよく使う”{sup:a}”がうまく変換されない、という点です.Stataに内蔵されているグラフではきちんとa乗として表示されますが、このコマンドはそういうわけにいかないようです.”eGFR, ml/min/1.73{sup:2}” とそのまま出てきてしまいました.
問題なのはそれくらいであとは圧倒的に便利です.ぜひ使ってみてください.


コメント
[…] ちなみにこれらのラベルは、グラフを描くときにも、先日ご紹介したtable1_mcを使うときにもそのまま表示されます.なのでできるだけ始めに定義しておくと楽です. […]