
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、今回は2カ月ぶりの更新となってしまいました.先月は論文投稿ラッシュでついに月2本のノルマを達成できませんでした.熱心な読者の方(?)からは更新楽しみにしてくださっていると温かい応援のお言葉をお伝えいただくことが時々あり、励みになっています.
そんな応援に応える形で、何とかネタを探しておりましたところ、本日データの加工をしているときに使った工夫をご紹介しようと思い立ったわけです.
今回実施したデータ加工は、
「全サンプルのデータ」
「ケースのみのデータ」
という珍しい組み合わせのデータセットをもらったところから始まりました.
データの加工を使用と思ったら、それぞれの識別子が削られた状態で渡されたことに気づいたのです.
つまり、ケースのデータは、全サンプルのデータに包含されるが、対応する識別子(ID)がないためにCaseとControlのフラグが立てられない!という事態になりました.
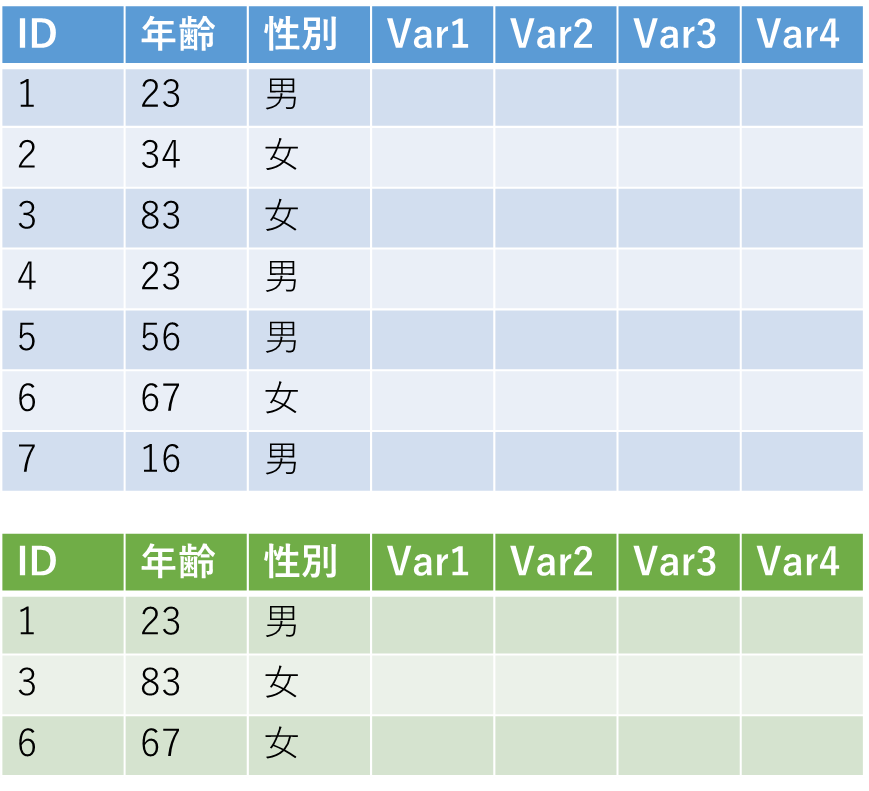
こんな風に入っていれば、IDを基にして簡単に紐づけることができるのですが、IDがないと、他の情報で照合していかないといけないので面倒です.
ではどうしたらいいでしょうか?ぱっと思いつくのが、
「最初にデータを上下で重ねて、いっぺんに同じレコードを取り除く」
みたいなことですが、果たしてこんなことできるでしょうか?
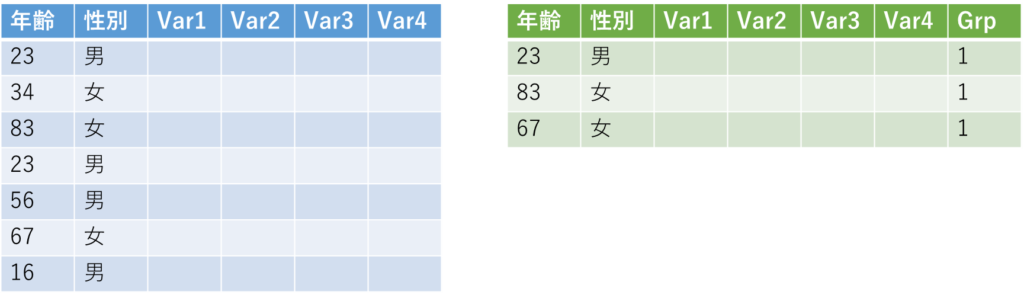

これで並べ替えて、Caseではないほうを消す、というのが手っ取り早そうなのですが、問題はデータが多くて、同じ変数の組み合わせを持つ症例が複数にわたると厄介です.
そこで、以下のように考えることにします.
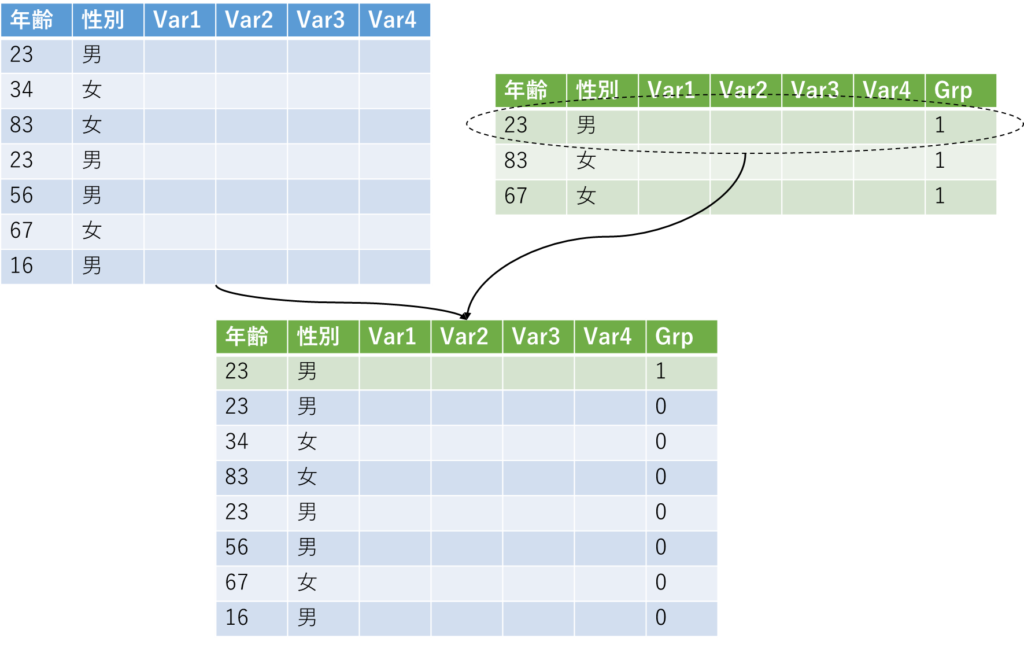
ケースの方のデータセットから上から順番に一人ずつ抜いてくるのです.そしてその下に全症例のデータセットを結合し、連結するためのキーとなる情報(例えばここでは年齢と性別ですが)が一致するように並べ替えます.
.sort 年齢 性別 Grp
とやって、Grp=1の症例の直上にいる症例を消す(drop)、というやり方です.
そして新しい症例に置き換わったらそれをセーブして、次の症例のときに結合します.
つまり、結合するためのデータセットは常に更新していきます.
import excel "Caseのデータセット.xlsx", firstrow clear
gen casecontrol = 1
gen order=.
save cases, replace
use cases, clear
local n=_N /* Caseの人数を覚えさせることで、回すループの数を決定 */
forvalues i = 1/n' {
preserve
display`i' /* 何番目のループかを明示する */
use cases, clear
qui keep in `i' /* 何番目の症例を残すか明示する */
quietly append using all /* 全患者データ⇒徐々に玉虫色にケースが混じってくる */
gsort 性別 年齢 order -casecontrol
qui drop if casecontrol ==0 & casecontrol[_n-1] ==1 & order[_n-1]==.
/* 同一属性をもつ症例を消去する */
replace order =`i' if order ==. & casecontrol==1
quietly save all, replace
restore
}このようにすればいつの間にかcasecontrolが1か0になってすべての症例が全患者データに組み込まれます.
こんなデータ加工、はっきり言って需要ないかもしれません.
でも考え方自体はいろいろな場面で応用できると思いますので、ぜひいろいろとお試しください.


コメント