
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、理論編でmi impute mvnの説明の中で、
「MCMCを使うので代入実行後に収束判定に関する診断をする必要がある」
という記載をしましたが、その具体的な方法について説明したいと思います.
また、それ以外にも重要なポイントや、自分自身今まで勉強してこなかったことなどを含めて記事にしてみました.独学であるが故の初歩的な間違いなどあるかと思いますので、その場合にはコメントなどでお知らせくださると助かります.
なお、参考にしたのはLightstone社のWebinar及びUCLAのサイトです.
1.データセットを展開してMI準備する
ではネットがつながる環境で、以下のコマンドを実行してみましょう.
webuse mheart8s0, clear /* データセットを展開 */
mi describe /* 欠損の状況を記述 */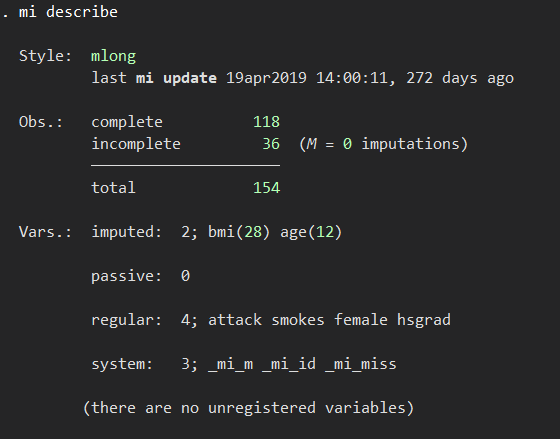
これによると代入される変数としてbmiが28、ageが12欠損していることがわかります.
attack, smokes, female, hsgradは欠損なくそろっていることになります.(注:ここに欠損している変数をいれてしまうとその変数が欠損している症例がリストワイズに除かれてしまうので注意)
まずはComplete-case analysisでOutcomeであるattackに対しての多変量解析を行いましょう.
logistic attack age bmi smokes female hsgrad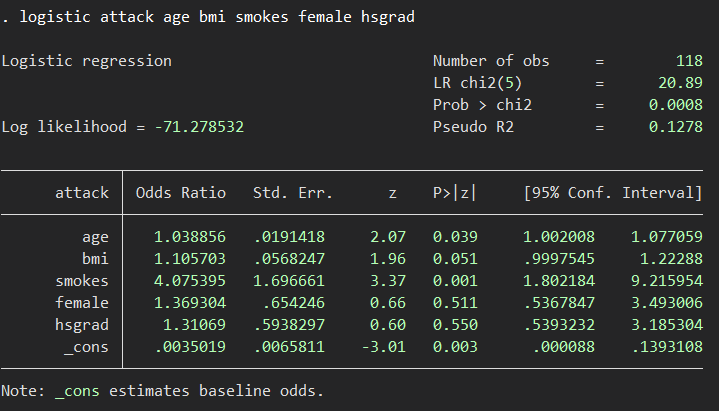
本来は154例あるはずが118例になっています.
2.多重補完の実行(MVN)
次に、MVNでMIをしてみます.
mi impute mvn age bmi = attack smokes hsgrad female, add(10)欠損した2つの変数bmi, ageに対し、10セットの新しいデータセットが準備されます.
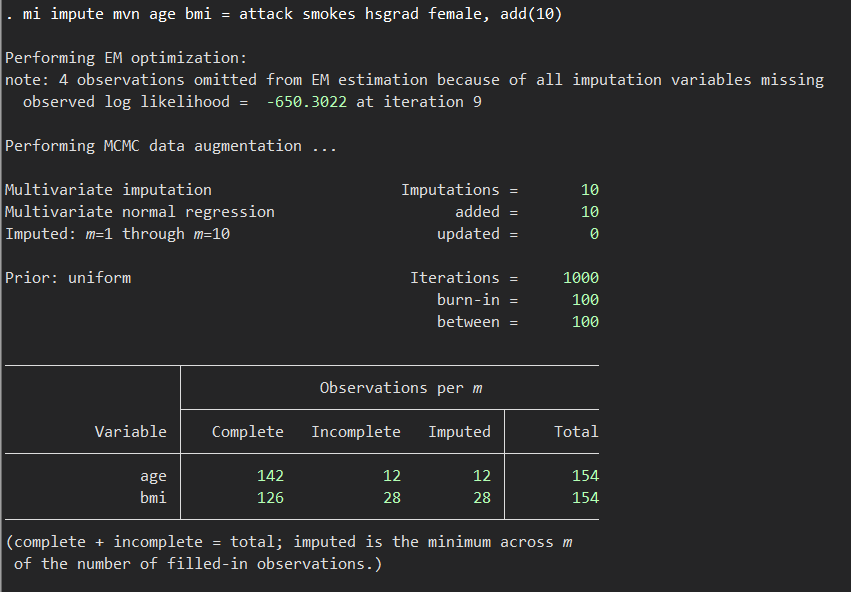
この中に出てくるパラメータを少しだけ解説します.
- imputations, added: 代入セット数のことで、この場合は10セット
- iterations: 繰り返しの数
- burn-in: number of iterations before the first set of imputed values is drawn, ということですので、最初のセットが作られるまでに繰り返した演算の回数の上限ということでしょうか.
これよりも上の部分で、observed log likelihoodの横のiteration 9というのは先日のWebinarを聞く限りでは、「代入値の初期値を求めるEMアルゴリズムの繰り返し計算回数」という説明がありました.これが100より小さければいい、という説明をしていました.
さて、代入後のデータセットで同じくoutcomeであるattackが生じるのに関連した因子を探してみます.
mi estimate : logistic attack age bmi smokes female hsgrad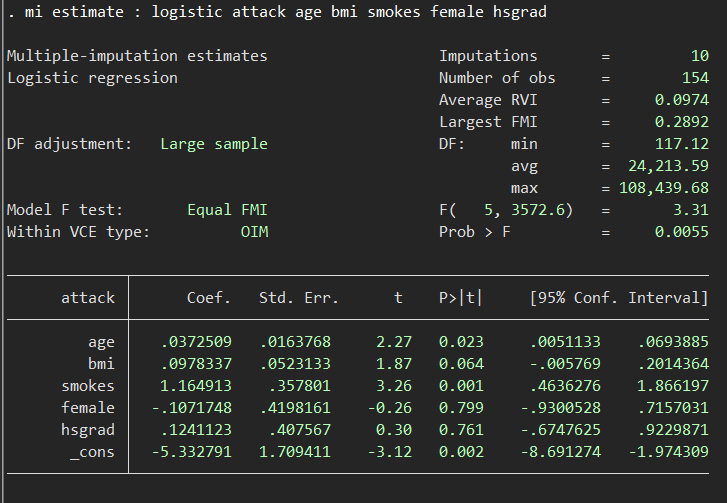
P値だけに着目するとあまり大きくは結果に変化がないように見えます.しかしここでLargest FMIというところの数値をみてください.これは欠損した情報の割合を表すのだそうです.目安としてはこの100倍、つまり小数点以下の2桁の数値よりも多いセット数での代入がよい、ということのようです.
ですか今回はこのまま進めてみたいと思います.
3.MCMCの収束を診断する
mi impute mvn bmi age = attack smokes hsgrad female, mcmconly burnin(2000) rseed(23) savewlf(wlf, replace)
save dataset, replace
use wlf, clear
tsset iter
tsline wlf, ytitle(Worst linear function) xtitle(Burn-in period)
ac wlf, title(Worst linear function) ytitle(Autocorrelations) ciopts(astyle(none)) note("")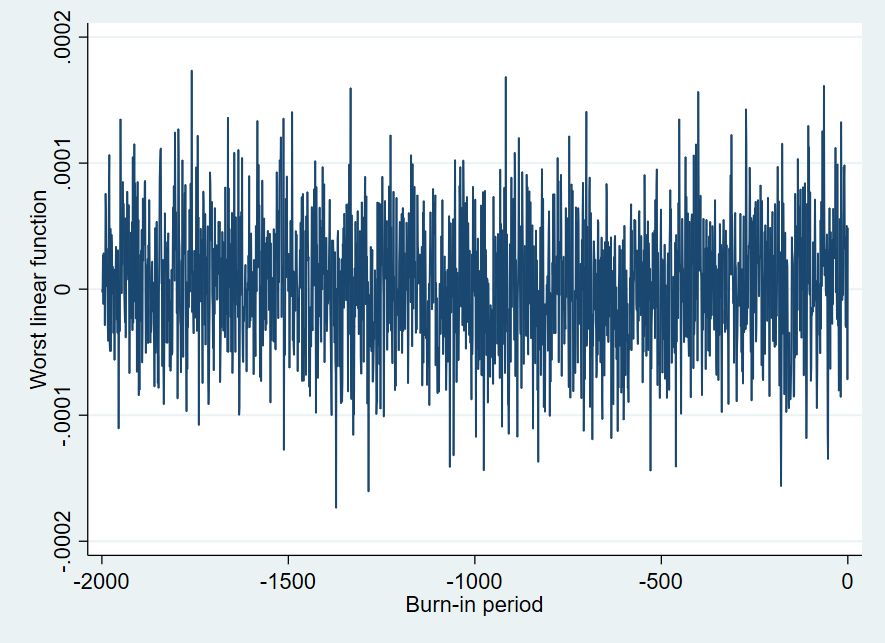
関数値が定常状態になっている=横にゆらゆらっとした感じになっていればよいとのことです.(この辺は感覚的なものなんでしょうかね)
続いてその次の行のグラフを描いてみますと、下のような棒がたくさん出てきます.できるだけ短いlagで0に収束しているほうがよいということでしたので、これは「非常に良い」ということになるのでしょうね.

(2021/3/1追記)ちなみにこれはmi impute chainedでも実施する必要があるんだそうです.詳しくはMIのPDFマニュアル155ページを参照ください.
さて、先ほどの結果ですが、セット数を30に増やして実施してみたところ、少し結果が変わりました.
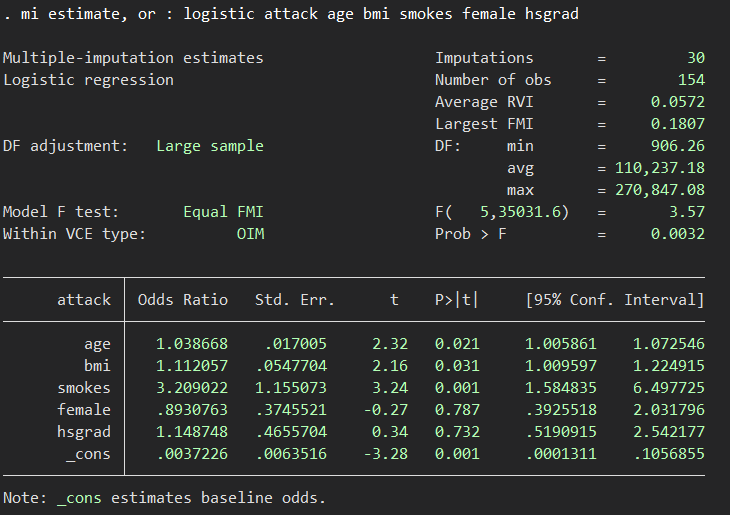
bmiが有意になりました.なんとなくチャンピョンデータか!とか言われそうですけど、代入回数に対する一定の基準を根拠に持てるので強気になれそうですかね(笑)
まとめ
今回は多重代入を行った後の評価方法についてまとめてみました.Lightstoneのセミナーはやっぱりいいなぁと思います.面白そうなラインナップの講義が準備されているようですので落ち着いたらまた東京に足を運んでみようと思います.


コメント