
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、今回も前回に続き、ちょっと発展的なグラフ作成を行うためのプログラムを紹介したいと思います.本日のお題は Sankey diagram (plot) です.
1.Sankey diagramとAluvial diagram
皆さんは、Sankey diagramというグラフの手法をご存知でしょうか?
工程間の流量を表現する図表である。矢印の太さで流れの量を表している。特にエネルギーや物資、経費等の変位を表す為に使われる。 Sankeyの名前の由来は1898年に初めてこの形式の表を用いた公刊物(Minutes of Proceedings of The Institution of Civil Engineers中の蒸気機関におけるエネルギー効率についての記事)の著者であるアイルランド人M.H.サンキー(en)に因む。
Wikipedia
一連のプロセスを時系列的に並べて矢印でつないだものがフローチャートだとすると、そこに量的な流れを主に組み込んだものがSankey diagramというグラフです.
しかし、Sankey diagramの話によく登場するのが、1812年から翌年にかけて行われた、ナポレオンによるモスクワ遠征の行程で兵力がどれだけ減ったかを図示したものです.
当初42万もいた兵力がモスクワ到着時に10万に減り、パリに帰還した折にはわずか1万にまで減っていました.
実際にはこのグラフはSankeyが初めて示したグラフよりも50年以上も前に作成されたものですが、考え方としては同じです.
「何か特定のパラメータの時間的な流れと、状態の偏移を量的に表現したグラフ」
といった感じに定義できるのではないかと思います.
一方、Sankey diagramとよく似ているけれど、その亜型みたいなものとして、alluvial diagram (plot) というものがあります.
これらはよく似ていますし、同じように扱われたりもしています.
たとえばLightstoneで扱っているOriginという作図ソフトでも「別名」と書かれているくらいです.
厳密な違いについてはいろいろな人がいろいろなことを言っているので、どれが信頼に値するか、なかなか難しいところなのですが、あるWeb siteの記載がわかりやすかったので、一応そういう違いがあるんだなーくらいにとらえてもらうのがいいのではないかと思います.
まず両者の共通点としては、ノードと呼ばれる節目とそれをつなぐ線(arc)で構成されているということです.さらに、
http://www.datasmith.org/2020/05/02/alluvial-plots-vs-sankey-diagrams/
- どちらの図でも、ノード(節目)は縦棒で表され、その高さは「数」または「量」の考えを伝えている
- どちらの図でも、ノード間のリンクは、その太さがノードの高さに関連し、ノードの高さと同様に「カウント」または「ボリューム」をコード化する曲線で構成されている
- どちらの図でも、ユーザーは通常、図全体の「縞模様」を強調して、その縞模様がさまざまな点でどの程度の幅を持つかを確認する
それで、違いについて、まずalluvial diagramでは
http://www.datasmith.org/2020/05/02/alluvial-plots-vs-sankey-diagrams/
- 対象としている集団がどのように各次元のカテゴリーに配分されるかを示す
- 左/右の位置には特に意味はなく、次元はどのような順序でもよい
- ノードは列で並べられる
- 集団の特徴同士がどのように関連しているかを示すのに便利。例えば、「特徴AとBを持つ人は何人いるか、Bを持っているがAを持っていない人は何人いるか」といった質問に答えることができる
時系列に並んでいるわけではなく、違うカテゴリ同士の組み合わせがどのようにまじりあっているか、クラスター間の関係性を示すのに役立ちそうです.
Sankey diagramでは、
http://www.datasmith.org/2020/05/02/alluvial-plots-vs-sankey-diagrams/
- ある状態から別の状態への量の流れを示す
- 左右の位置は、動きや変化を示す
- ノードはどこにでもあり、アルゴリズムによって配置されなければならない
- 何かの量、サイズ、または人口を追跡する必要があるフローやプロセスを示すのに便利である。たとえば、「システムAのエネルギーのうち、システムBとCから来た量はどれくらいで、そのほとんどはどこに行くのか」といった質問に答えることができる
alluvial plotは主に多次元データ解析のケースで適用されるようです.異なる次元間の頻度や割合、そしてそれらがどのように互いに関連しているかに重点が置かれます.
一方で、Sankey diagramでは、フローが強く意識されます.プロセス全体のさまざまな段階間の量の視覚化を必要とするケースで適用されます.流れの中に入ってくる部分と出ていく部分の量を可視化することができるので、工程内で特に中心的な役割を果たすものが何かを示したり、流れの中で失われている部分を特定したりすることに長けています.
JAMA DermatologyでSankey diagramの例が掲載されていました.Hidradenitis Suppurativaという疾患に対する生物学的製剤の変遷を記述しています.
一方で、alluvial plotとしての例がこちら.ADHDの患者さんたちの臨床徴候の組み合わせに関するクラスターを理解するのに役立っています.
2.Stataでado fileを探してみる
Stataで描けたらいいよなぁと思って以前調べてみたのですが、ヴィジュアル的にあまりイケてなかったのでOriginを使って描いていました.
Stataでhelp sankeyと打ってみると、一応下記のado fileが出てきます.
sankeyplotのほうを入れてみましたが、
clear
set obs 987
gen edu_0 = _n <= 500
replace edu_0 = 2 if _n > 900
gen edu_1 = runiformint(0,2)
lab def edu 0 “Low Edu.” 1 “Medium Edu.” 2 “High Edu.”
lab val edu_0 edu_1 edu
sankeyplot edu_0 edu_1
sankeyplot edu_0 edu_1, percent ///
blabel(vallabel) blabformat(%3.1g) ///
colors(gs6%70 gs10%70 gs14%70) ///
legend(r(1) symx(*0.5) region(lc(white))) ///
xlabel(0 “1st Gen.” 1 “2nd Gen.”) xtitle(“”) ///
ylabel(,angle(0)) ytitle(“Relative Frequencies”) xsize(7) ///
title(“Educational Mobility Across Generations”)
といれると、
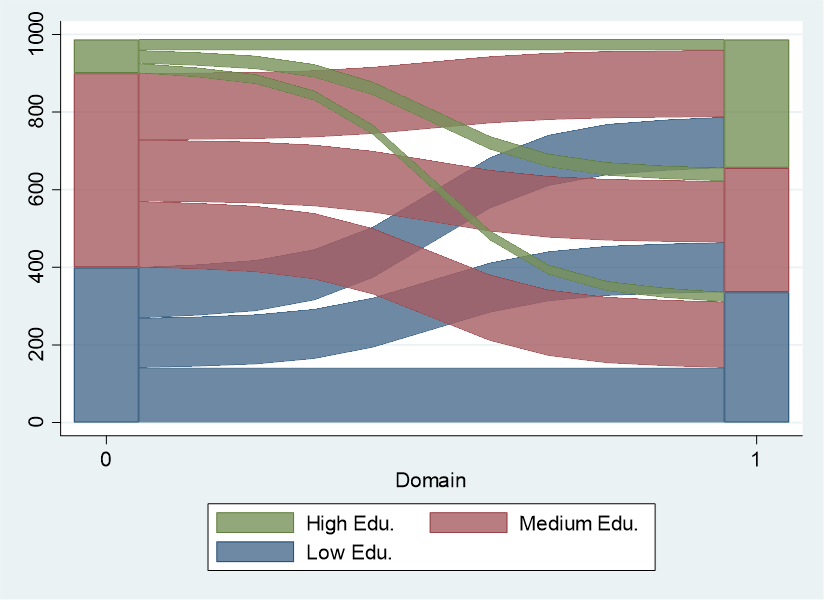
最近フォローするようになった経済学者の人が美しいSankeyとalluvialを公開してくれていたので、それをご紹介します.
net install sankey, from(“https://raw.githubusercontent.com/asjadnaqvi/stata-sankey/main/installation/”) replace
net install alluvial, from(“https://raw.githubusercontent.com/asjadnaqvi/stata-alluvial/main/installation/”) replace
必要に応じて以下のado filesもインストールしましょう.
ssc install palettes, replace
ssc install colrspace, replace
ssc install schemepack, replace
set scheme white_tableau
1.Sankey diagram
まずはSankey diagramから.以下、サンプルファイルをゲットしてください.
use “https://github.com/asjadnaqvi/stata-sankey/blob/main/data/sankey2.dta?raw=true”, clear
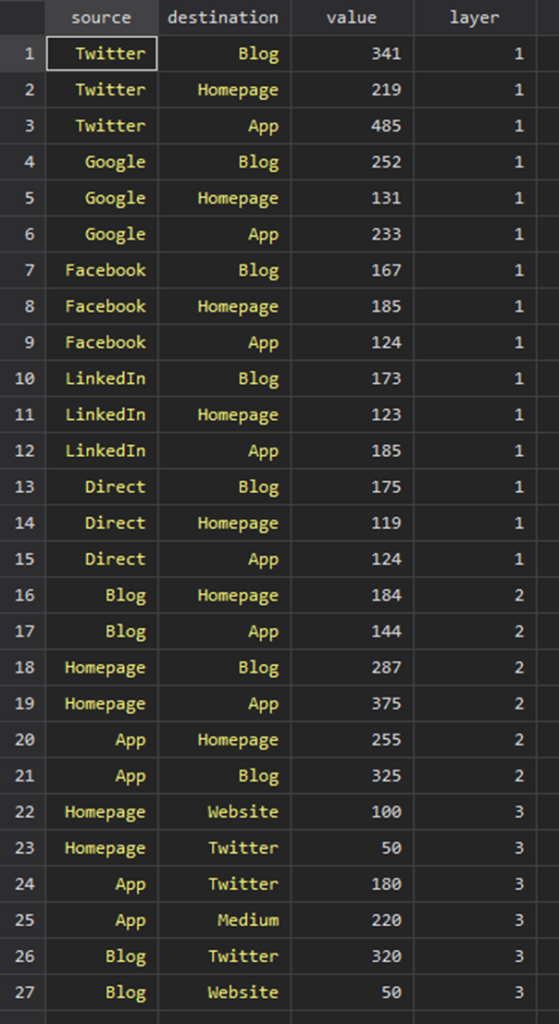
データは縦持ちのデータになっています.
Sankeyはあるプロセスの出入りを時系列にそって記述することが本質なので、入り口であるsource、出口であるdestinationがあります.そして時系列を表現するために時点を表すlayerがある、という構造です.
sankey value, from(source) to(destination) by(layer)
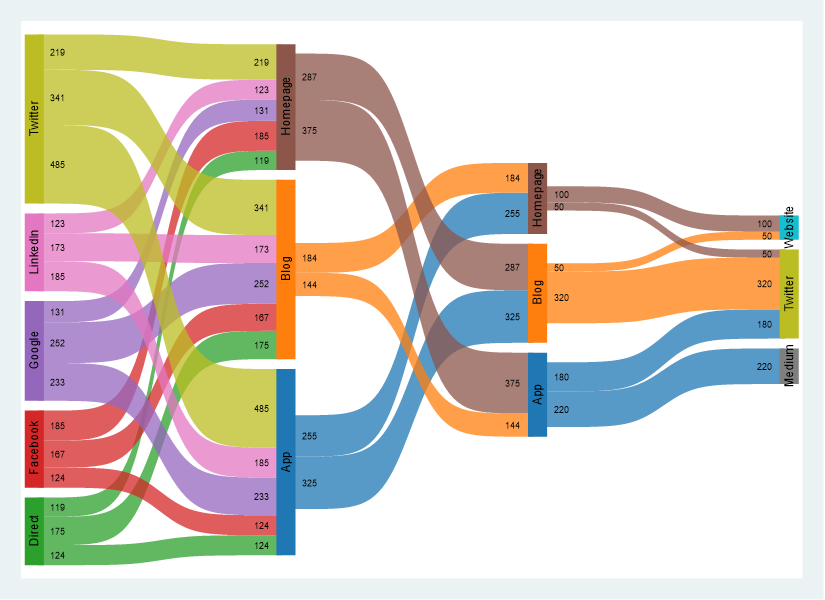
私はTwitterから入ってBlogに行きましたので多数派です.さらにそこからHomepageに行きました.
こんな感じで、いくつかの枝分かれの仕方をするのですが、Web siteを訪れる人やFacebookを見に来る人がその後ちゃんとブログに記事を見に来てくれるか、どんなjourneyをたどって行くのかを表現するのによいと思います.
さらに細かい設定方法についてはNaqviさんのサイトをご覧ください.
2.Alluvial diagram
次にAlluvial plotです.
sysuse nlsw88.dta, clear
alluvial race married collgrad smsa union
こちらのデータセットは基本的には横持ちです.
violin plotを作成するときにも使ったデータセットでしたね.
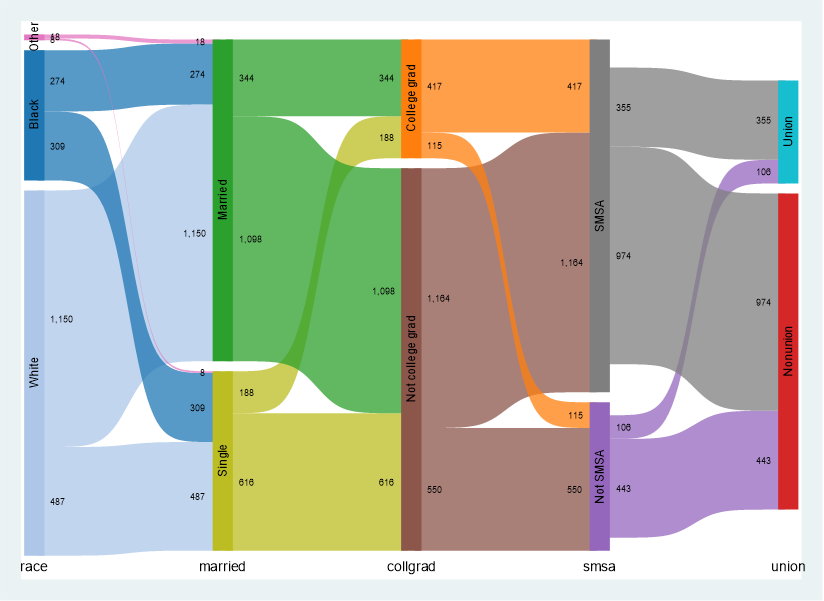
人種、婚姻状態、学歴、SMSA(standard metropolitan statistical area、米国で標準大都市地区)、労働組合加入状況のそれぞれの関係性を横断的に可視化することができます.
いかがでしたか?このようなグラフによる可視化もありますので、参考になればと思います.
それにしてもやはりいまいちSankeyとAlluvialの違いが明確ではない気がします.そこまで気にしなくてもいいのかもしれませんが….
ちなみに、Origin proではarcの色味をグラデーションにすることができるのでさらに見やすいというのが特徴です.今回のプログラムではどこまでのことができるのか、まだまだ習熟したわけではないので、さらに詳しく見ていきたいと思います.


コメント