
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、本日の記事は、エクセルファイルにたくさんのシートが連なっていて、それをデータシートに落とし込むための作業を自動化する方法をご紹介したいと思います.
1.対象者別のシートになっているデータセット
エクセルシートでデータを頂くときに時々経験するのが、
”対象者ごとに別のシートでデータが格納されている”
状況です.これは結構うんざりしてしまうのですが、それを解決する方法をまとめたのが今回の記事になります.
1.サンプルデータセット
本日使うデータセットを置いておきます.
作りとしては、シート名が対象者の研究IDか何か識別子となっている状況を想定してください.
このときそのエクセルをdescribeして、return listを実行するとシートの詳細を知ることができます.
import excel "filename.xlsx", describe
return list
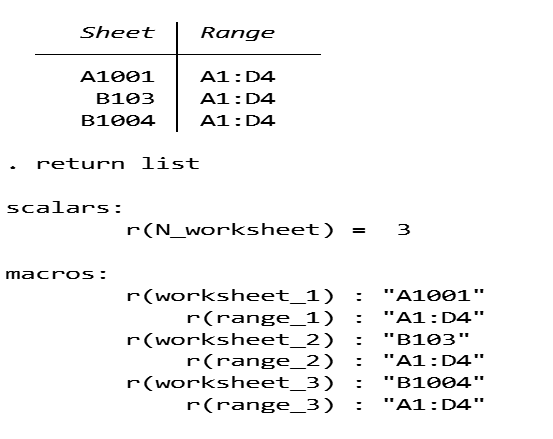
これをみると、macroの部分が取り出せそうというのがわかると思います.
2.Stata形式で一つ一つデータセットを作成する
そこで改めてreturn listに入っているscalar値とmacroを取り出します.
シートの数がscalar値 r(N_worksheet) として取り出せますので、1番目から順番にr(N_worksheet)番目まで繰り返すループを組みます.
そしてどんな名前のシートを取り出すかを指定し、セルの範囲もmacroで取り出すことができます.
以上をプログラムに落とし込むと以下のようになります.
import excel "filename.xlsx", describe
return list
clear
forvalues i=1/`r(N_worksheet)' {
import excel using "filename.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_i')') firstrow
generate id =r(worksheet_`i')
save $file_`i'.dta, replace
clear
} 最終的にはこれをlong dataにしてからappendでどんどん縦につないでいくこともできるかと思います.一つ一つ開いていく作業が自動化されるのでかなり楽になるとは思います.(そもそもこんなデータで作らないのが一番いいんですけど…)
(2021.10.27追記)先日、150枚くらいシートが入ったエクセルファイルを渡されてデータを整えてみたのですが、なぜかエクセルのインポートが一つ目のワークシートしか入らない、という事態が発生しました.
原因ははっきりしませんが、forvalues … の構文のすぐ下に、またエクセルファイル全体のdescriptionとreturn listをおいて事なきを得ました.うまくいかないときにはこういった方法もお試しになるとよいかもしれません.
import excel "filename.xlsx", describe
return list
clear
forvalues i=1/`r(N_worksheet)' {
import excel "filename.xlsx", describe
return list
clear
import excel using "filename.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_i')') firstrow
generate id =r(worksheet_`i')
save $file_`i'.dta, replace
clear
} なんだか無駄な構文に見えるんですけどね…
それと、さすがに150個のシートの詳細がdescribeとreturn listでたくさん表示されてしまってウザいので、quietlyに実施してもよいと思います.
qui {
import excel "filename.xlsx", describe
return list
}
clear
forvalues i=1/`r(N_worksheet)' {
qui {
import excel "filename.xlsx", describe
return list
}
clear
import excel using "filename.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_i')') firstrow
generate id =r(worksheet_`i')
save $file_`i'.dta, replace
clear
} 3.Working directoryの指定
ちなみに、エクセルファイルやCSVを取り出すときに自分はworking directoryをglobal macroで最初に指定しています.
“wd”という名前でファイル名の手前までの文字列を記憶してしまえば長ったらしい名前のファイルを書く必要がなくなります.別のフォルダに格納しているデータを取り出したりするのもできますので、いくつか設定してもいいと思います.
global wd "C:\User\...\" /* working directory名 */
import excel "${wd}filename.xlsx", describe
return list
clear
forvalues i=1/`r(N_worksheet)' {
import excel using "${wd}filename.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_`i')') firstrow
generate id =r(worksheet_`i')
save ${wd}file_`i'.dta, replace
clear
} 2.すべてを一つのデータベースにまとめる
ここまでくるとやはり一つのデータベースにまとめたくなるのが人の性.ということで、実際に上記のデータセットを積み重ねていきます.
このとき、中間データを生成して後からまとめて消去する、という方法も併せてご紹介します.
global wd "C:\User\...\" /* working directory名 */
import excel "${wd}filename.xlsx", describe
return list
clear
forvalues i=1/`r(N_worksheet)' {
import excel using "${wd}filename.xlsx", sheet(`r(worksheet_`i')') cellrange(`r(range_`i')') firstrow
gen id =r(worksheet_`i')
save ${wd}tempfile_`i'.dta, replace /* 中間データとしていったん保存 */
clear
}
use ${wd}tempfile_1.dta, clear
forvalues i = 2/`r(N_worksheet)' {
append using ${wd}tempfile_`i'
/* 順番に結合してきます */
}
save ${wd}file, replace
!del ${wd}temp* /* temp という名前を頭につけておいたものをすべて消去 */ここで出てきた、”!del” というコマンドですが、名前に共通した部分をつけておけば一気に消せるという代物です.ワイルドカードを前後につけることができますので、中間ファイルを作ってやる場合にはこれも一つの方法になるでしょう.
ちなみに、tempfileというやり方もありますが、こちらはなぜかIDの設定がうまくいかず.たぶん桁数が違っていたからだと思うのですが、そういうこともあるので、中間ファイルをいったん生成しておいて後で消す、というオプションは役に立つときが来ると思います.
まとめ
エクセルのシートが複数存在するようなシートの展開についてまとめてみました.
こういうファイルはとても使いにくいし重たいので開きにくいし、あまりお勧めはしないのですが、受け取る側としては文句は言えませんので、こういうデータも処理できるオプションを備えておくとよいかもしれません.


コメント
[…] 複数のシートが入ったエクセルファイルのインポートをプログラムする方法は、以前の記事にありますが、今回は最初に1行目の値を変数名にしないことにしてインポートします.(同じデータを利用しています) […]
記事の途中で、cellrange(`r(range_`i’)’) firstrow
が改行されてrange_`i’の`が消えている部分がありました。
コピペしたらエラーが出たので気がつきました
({の前に全角スペースがありました。これも記事にする際に勝手に変わったのだと思います。)。
このオプションは無くてもシート全体を読み込んでくれるので無しでも良いかもしれません。
また!から始まるコマンドはシェルスクリプトを実行しているようですが
Macでは!delが働きませんでした。
!rmに変更したら全く同じ結果になりましたのでご報告しておきます。
お知らせいただきありがとうございます!
良く消えるんですよね~。ご利用の方は気をつけてください!
WindowsとMacで少し仕様が違うんですかね~。勉強になります。Macユーザも結構いるので、
そういう人達への情報提供の際に伝えるようにします!