このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
今日もデータを整える際のTipsについてまとめてみました.
どんなデータかというと、下の図のように、各人に対していろいろな検査項目(var1, var2,…)を測定していて、しかも繰り返し受診しているというものです.
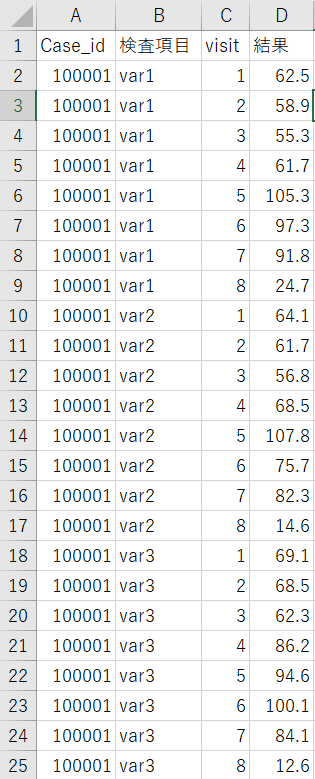
このようなデータは縦持ちデータと呼ばれますが、このままでは通常の統計解析を行うのに都合が悪いことが多いです.
なので、何らかの形で横持ちのデータに変換することが求められます.

ここで、このデータセットの特徴を述べておくと、個人を表すIDは1つですが、繰り返しの要素が複数ある、ということです.
縦持ち横持ちの変換には、”reshape”コマンドを用いますが、i(解析単位), j(繰り返し符号) それぞれに入る要素が一つと限らないというのが厄介な点です.このような場合、分解の方法は2つあります.
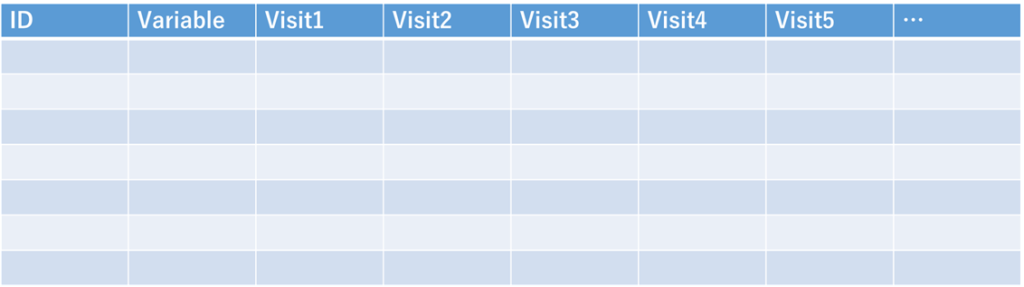
一つ目は、IDと変数名をセットにして、一塊に扱うグルーピングで、横に連なるのはVisitごとの値です.
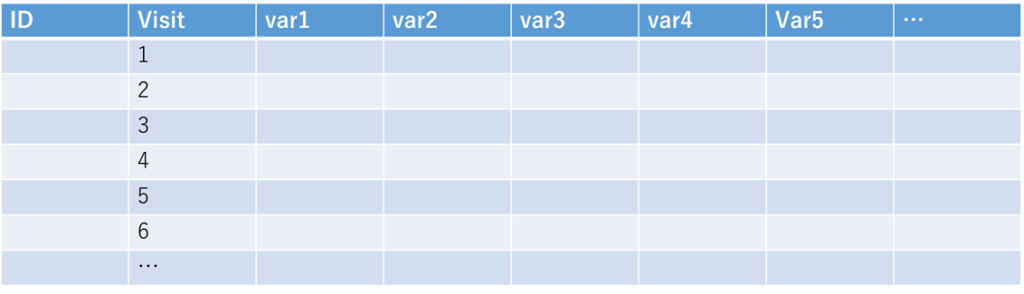
次は、項目が横に連なり、IDとVisitをペアにして、それぞれの組み合わせが1行ずつになるようにグループを作る方法です.検査項目をVisitごとにまとめたいときなんかはこちらのほうが扱いやすいと思います.
コードとして書こうと思うと、以下のようになります.
ここで、検査項目が文字列の場合は、数字にしないとj()の中に入れることができません.
encodeを使ってそれぞれの検査項目名に対応する番号をStataに決めてもらいます.
*** 症例と検査項目のペアをひとセットとみなす方法.
import excel "labodatalong.xlsx", firstrow clear
reshape wide 結果, i(Case_id 検査項目) j(visit)
*** 症例とVisitのペアをひとセットとみなす方法
import excel "labodatalong.xlsx", firstrow clear
encode 検査項目, gen(labitem)
reshape wide 検査項目 結果, i(Case_id visit) j(labitem)
さて、実は二つ目のコマンドですが、これだけでは目的とした形のデータセットにはなりません.
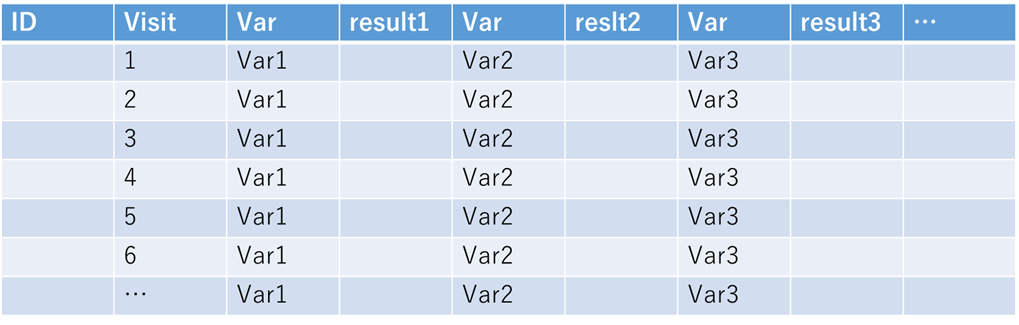
こんな感じで、変数名にresult1, result2, result3,… と入っています.これを本来の変数名であるvar1, var2, var3,…という風に変更したいですよね.これが一つや二つならいいのですが、10個超えてくると何とか楽したくなります.そこで、以下のようにループを組んでみましょう.
*** 症例とVisitのペアをひとセットとみなす方法
import excel "labodatalong.xlsx", firstrow clear
encode 検査項目, gen(labitem)
reshape wide 検査項目 結果, i(Case_id visit) j(labitem)
forvalues n = 1/3 {
gsort -結果`n'
local v = 検査項目`n'
rename 結果`n' `v'
}
drop 検査*
sort Case_id visitトリッキーなのが、gsort -結果`n’ の部分ではないでしょうか?
何でこんなことをするのか?それは、もしこれの一番上のフィールドが欠損だった場合、変数名にフィールドの度数を利用することができない、取り出せないからです.(フィールドの中の文字列を変数としてlocal変数に格納する、というのが正確な手順ですが。)
最後に検査項目を消去してきれいに並べ替えましょう.
Visitの1番最初だけ取り出したい場合は出来上がったデータベースの中でVisit=1だけ残せばよいですね.
簡単です!
ぜひお試しあれ!


コメント