
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、本日の記事は、同じ形式のエクセルファイルを受け取ったときに自動的に処理する方法をご紹介したいと思います.
以前の記事では、1つのエクセルファイルにたくさんのシートが連なっているときに自動処理するためのプログラムを提案しましたが、今回は、全部バラバラのファイルで渡された、というパターンです.
さらに、ファイル名がIDとか実名だったりするとそういった個人を特定する情報をさっさと消したくなりますね.
ということで、作業フローを示します.
0.xls2dta コマンドを入手
1.受け取ったファイルを1つのフォルダに格納
2.Stata形式にデータを変更
3.ファイル名をデータセットに取り込む
4.データセットをappendし、中間ファイルを削除
以下、解説していきます.
1.準備
まずはxls2dtaというコマンドを入手してください.⇒help xls2dta
次にサンプルのデータセットをこちらに置いておきますので、例によって自己責任でダウンロード・ご利用ください.(IDは架空のものであり、個人由来の情報は一切含みません)
2.実際にやってみる
以下のような流れとプログラムを実行します.順番に解説してまります.
*Excelファイル一式を格納するフォルダのDirectoryを指定
cd "C:\Users\...."
*フォルダ内のExcelファイルをすべてStata形式に変換する
xls2dta, firstrow
*** すべてのファイルをappend(結合)して1つのファイルにする
*ファイル名をIDにして新たな変数に置き換える
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist{
use `file', clear
gen id = "`file'"
replace id = subinstr(id, ".dta", "", 1)
save , replace
}
*作成したデータセット(Stata形式)をすべてappendで結合して、ファイル名からIDを消去
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist{
append using `file'
save appended, replace
}特定のフォルダの中にすべてのデータセットを入れておきます.これを格納したフォルダのPathをコピーしましょう.
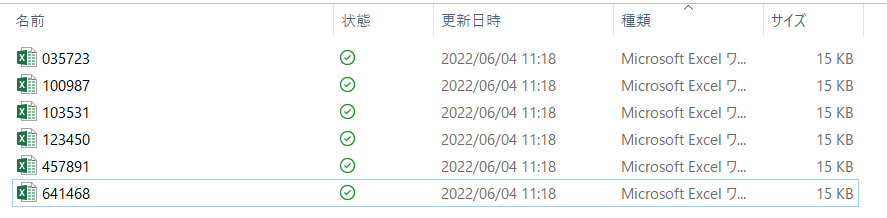

Pathを指定するとどこで作業するかを指定できます.
*Excelファイル一式を格納するフォルダのDirectoryを指定
cd "C:\Users\...."
*フォルダ内のExcelファイルをすべてStata形式に変換する
xls2dta, firstrowこれで一発でStata形式に変換されます.
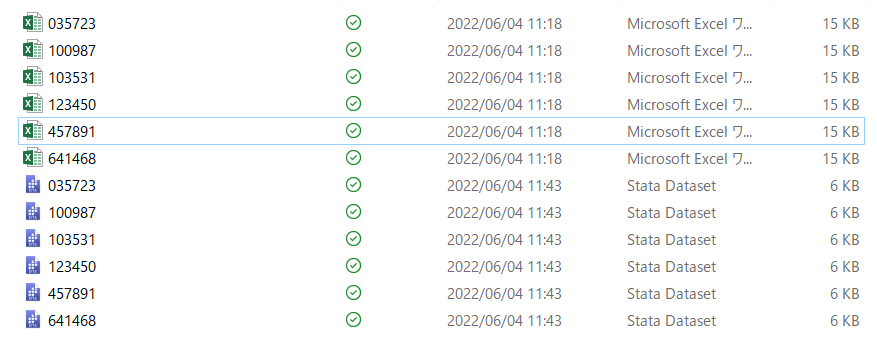
*** すべてのファイルをappend(結合)して1つのファイルにする
*ファイル名をIDにして新たな変数に置き換える
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist{
use `file', clear
gen id = "`file'"
replace id = subinstr(id, ".dta", "", 1)
save , replace
}idに”ファイル名.dta”という文字列が入りますので、.dtaを消さないといけません.それでsubinstrという関数を用いて”.dta”の文字列を削ります.
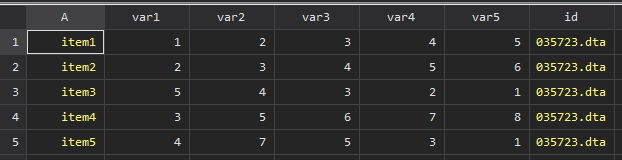
ちなみに中間ファイルにはIDが入ってしまいますので、それらはすべて削除しないといけません。
それを防ぐには、最初のステップでファイル名を連番にしてしまうというのも手です。
local index=1
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist {
use `file', clear
gen id = "`file'"
replace id = subinstr(id, ".dta", "", 1)
save `index++', replace
erase `file'
}foreachであっても連番がつけられるのは便利ですね.local変数に++をつけるだけです.
さて、最後のステップとして、データを結合していきます.
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist{
append using `file'
save appended, replace
}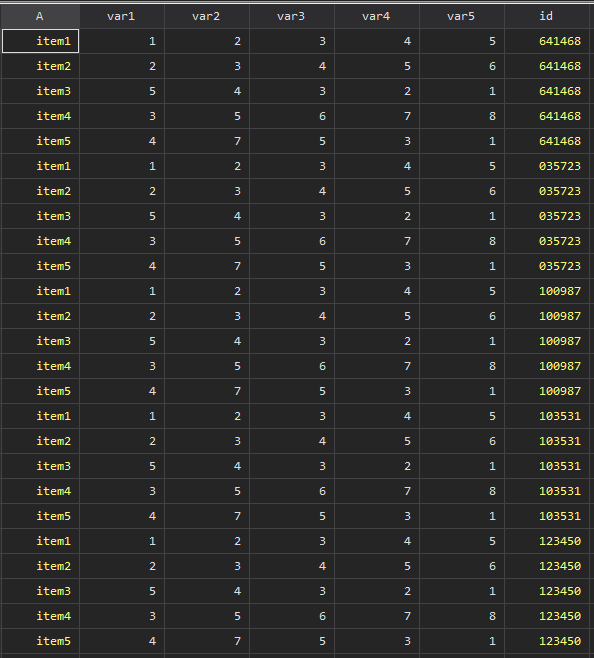
ということで出来上がりです.どうせ中間ファイルはすべて消去するので、あまり意味はないのかもしれませんが、先ほどのプログラムの続きを書いておきます.
xls2dta, firstrow
local index=1
local myfilelist : dir . files"*.dta"
foreach file of local myfilelist {
use `file', clear
gen id = "`file'"
replace id = subinstr(id, ".dta", "", 1)
save `index++', replace
erase `file'
}
*作成したデータセット(Stata形式)をすべてappendで結合して、ファイル名からIDを消去
forvalues file = 1/6 {
append using `file'.dta
save appended, replace
erase `file'.dta
}3.まとめ
いかがだったでしょうか?
IDをむき出しの状態のデータを受け取ったらすぐに加工しなければその後の処理に支障をきたしますので、このようなプログラムが今後研究を行う人に役に立つのではないかと思います.
参考になれば幸いです.


コメント