
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、本日の記事では、新規のバイオマーカーや変数を入れることによって予測確率が改善するかを表す、net reclassification improvement (NRI) をStataで実行するための方法を紹介してみたいと思います.
1.NRIとは何か
NRIについてわかりやすく説明すると、
| イベントあり | イベントなし | ||
| 予測確率上昇 | a | b | a+b |
| 予測確率低下 | c | d | c+d |
| a+c | b+d |
イベントが本当にあった場合には予測確率が上昇したほうがよい、つまりcは減り、aは増えるほうが良いですね.逆にイベントがない場合には予測確率が低下するほうがよいので、dが増えてbが減るほうがよいわけです.ということで、NRIは以下のように計算されます.
NRI = (a – c)/(a + c) – (b – d)/(b + d)
これを自動的に計算しているに過ぎないので、ぶっちゃけ自分で作れてしまうくらいの簡単なプログラムです.
ちなみに、se値は次の式で与えられます.ここで、
- PUE : イベントあり予測確率上昇の確率 a/(a + c)
- PDE : イベントあり予測確率低下の確率 c/(a + c)
- PUN : イベントなし予測確率上昇の確率 b/(b + d)
- PDN : イベントなし予測確率低下の確率 d/(b + d)
としたとき、
SE = sqrt(((PUE + PDE)/イベントありの数)+((PUN + PDN)/イベントなしの数))
で与えられます.ここから信頼区間の計算もできるということになります.
2.Stataでの実装(ado fileの利用)
StataではデフォルトでNRIを行うプログラムはありませんので、Userが作ったプログラムを使うことになります.
findit nri ここから調べていっても実はなかなか見つけにくいところに隠れています.同じく再分類を評価するintegrated discrimination index (IDI) と同じところにあるので、Stata ado fileであるnri, idiを一緒にインストールします.

ここからidiを選択して次の画面に行きます.
この中にidiもnriもありますので、これで基本的には解決です.Syntaxを確認すると、
nri outcomevar [new_marker varlist] [if] [in] [, ignoreold at(numlist)
pold(varname) pnew(varname) ]
アウトカム、新しい変数(バイオマーカーなど)、既存のモデルの変数群、という順番に並べていきます.lbwというデータセットを例に使ってみましょう.低出生体重になるかどうかを予測する、というテーマです.
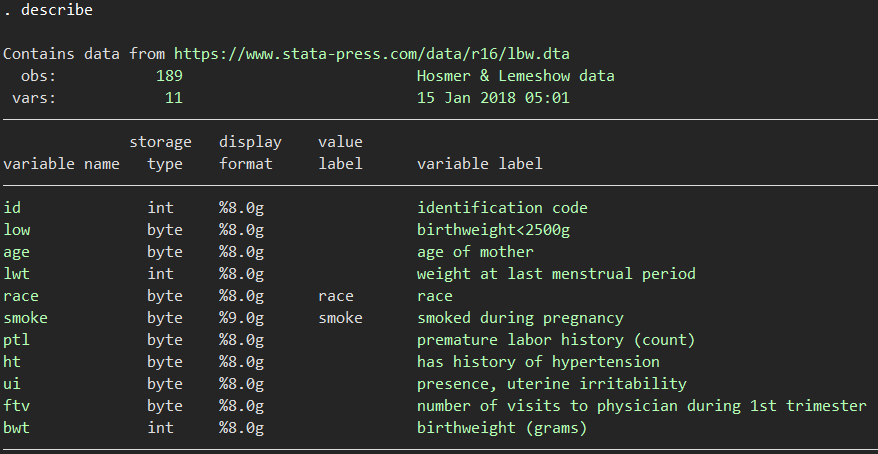
ここでは、lwtという変数(weight at last menstrual period)を組み込むことでモデルから予測される確率が向上するか、ということを調べてみましょう.
webuse lbw, clear
logistic low age race smoke ht ui
/* これをベースモデルとします*/
logistic low age race smoke ht ui lwt /* lwtを加えたモデルとします*/
nri low lwt age race smoke ht ui /* アウトカム変数 新しいマーカー ベースモデルの順に並べます */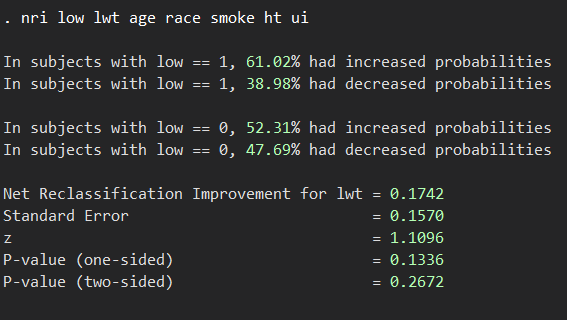
結論から申し上げると、これは有意ではないということになります.つまり、lwtを新しい変数として追加しても予測確率は有意には向上しないということを意味します.
3.ado fileではできないこと
しかし、このプログラムでは、新しい変数の組み合わせや、3つ以上のカテゴリを持つ名義変数は受け付けてくれません.新しい変数は必ず一つでなければならず、しかも連続変数か二値変数であることが必要です.
この場合には自力で何とかすることが必要です.しかし、原理さえ学んでしまえばあとはその応用ですので、自力でできるはず.まずは先ほどのプログラムを自力で書いてみます.
webuse lbw2, clear
nri low lwt age smoke ht ui race2 race3 /* アウトカム変数 新しいマーカー ベースモデルの順に並べます */
*** 自力作成のプログラム
logistic low age smoke ht ui
i.race
predict p
logistic low age lwt smoke ht ui i.race
predict p_add
generate improve = 1 if low ==1 & p < p_add
replace improve = -1 if low ==1 & p > p_add
replace improve = 1 if low ==0 & p > p_add
replace improve = -1 if low ==0 & p < p_add
count if improve ==1 & low ==1
local eventsup = r(N)
count if improve ==-1 & low ==1
local eventsdown = r(N)
count if low ==1
local events = r(N)
count if improve ==1 & low ==0
local noneventsdown = r(N)
count if improve ==-1 & low ==0
local noneventsup = r(N)
count if low ==0
local nonevents = r(N)
noi tab improve low
noi disp `eventsup', `eventsdown', `events', `noneventsup', `noneventsdown', `nonevents'
local pue = `eventsup'/`events'
local pde = `eventsdown'/`events'
local pun = `noneventsup'/`nonevents'
local pdn = `noneventsdown'/`nonevents'
local nri = (`pue' - `pde') - (`pun' - `pdn')
local se = sqrt(((`pue'+`pde')/`events')+((`pun' + `pdn')/`nonevents'))
local lb = `nri' - 1.96*`se'
local ub = `nri' + 1.96*`se'
noi disp %6.4f `nri', %6.4f `lb', %6.4f `ub'
local z = `nri' / `se'
local p = 2*normal(-1*`z')
noi disp %6.4f `p'一応結果が一致したことを確認できましたので、人種が3つのカテゴリー変数なので、これを加えることで予測が改善するかについて検討してみることにしましょう.
webuse lbw2, clear
logistic low age lwt smoke ht ui
predict p
logistic low age lwt smoke ht ui i.race
predict p_add
generate improve = 1 if low ==1 & p < p_add
replace improve = -1 if low ==1 & p > p_add
replace improve = 1 if low ==0 & p > p_add
replace improve = -1 if low ==0 & p < p_add
count if improve ==1 & low ==1
local eventsup = r(N)
count if improve ==-1 & low ==1
local eventsdown = r(N)
count if low ==1
local events = r(N)
count if improve ==1 & low ==0
local noneventsdown = r(N)
count if improve ==-1 & low ==0
local noneventsup = r(N)
count if low ==0
local nonevents = r(N)
noi tab improve low
noi disp `eventsup', `eventsdown', `events', `noneventsup', `noneventsdown', `nonevents'
local pue = `eventsup'/`events'
local pde = `eventsdown'/`events'
local pun = `noneventsup'/`nonevents'
local pdn = `noneventsdown'/`nonevents'
local nri = (`pue' - `pde') - (`pun' - `pdn')
local se = sqrt(((`pue'+`pde')/`events')+((`pun' + `pdn')/`nonevents'))
local lb = `nri' - 1.96*`se'
local ub = `nri' + 1.96*`se'
noi disp %6.4f `nri', %6.4f `lb', %6.4f `ub'
local z = `nri' / `se'
local p = 2*normal(-1*`z')
noi disp %6.4f `p'NRIは0.3434、95%信頼区間は0.0357から0.6511となり、P値は0.0287と有意になりました.
まとめ
さて、自力でプログラムを書けばちょっとした応用編はできるということがわかりました.実はこのプログラムは、ado fileの中身をみて参考にしました.特にSE値はP値の計算に必須ですので、どんな計算をしているのかをここでしることができれば自分のプログラムに反映させることができるということです.ちなみにintegrated discrimination improvement (IDI)でも同じように作ることができました.


コメント
[…] 以前の記事で、net reclassification improvement (NRI) やintegrated discrimination improvement (IDI)をStataでカスタマイズするための方法を紹介しましたが、今回はその続編です. […]
[…] これらを順に説明していきます.なお、Reclassificationについては以前の記事を参照ください.なお、こちらに掲げる項目はSteybergらがその著書や論文(Epidemiology 2010)に紹介しています. […]