
このブログでは、統計解析ソフトStataのプログラミングのTipsや便利コマンドを紹介しています.
Facebook groupでは、ちょっとした疑問や気づいたことなどを共有して貰うフォーラムになっています. ブログと合わせて個人の学習に役立てて貰えれば幸いです.
さて、今回は予測モデルについてまとめてみました.
1.予測モデルの一般的な流れについて
予測モデルを作成するにあたっては、TRIPODのガイドラインを参照するとよいです。しかしこれだけでは具体的に何をしたらいいかわかりません.
一般的な手順として以下のような流れになっていると理解するとよいと思います.
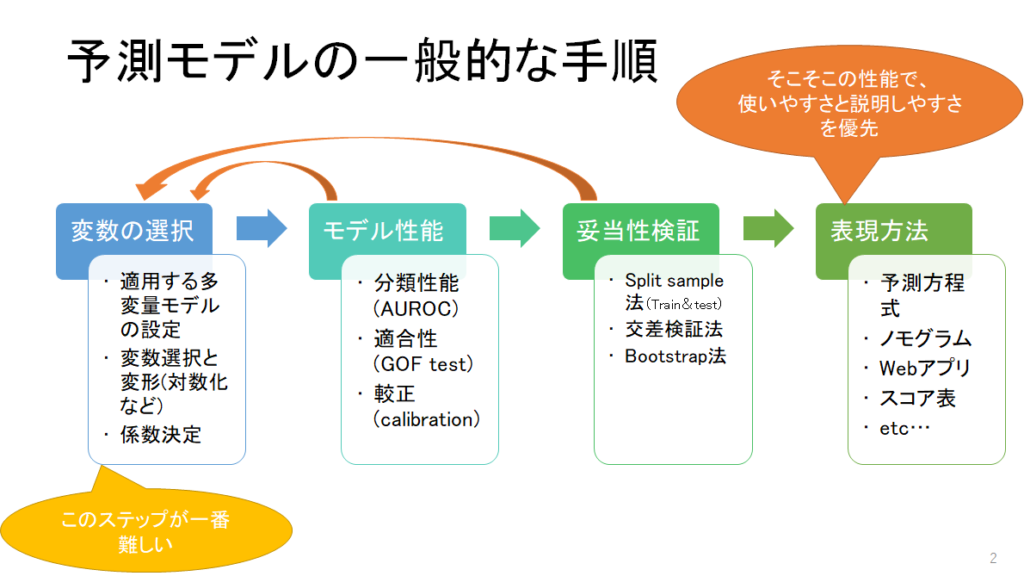
具体的に統計学的なアプローチとしては次の事項について、手順をまとめておくとよいと思います.
- 性能/適合度:Overall performance / Goodness-of-fit
- 判別:Discrimination → AUC, C統計量
- 較正:Calibration → 予測と実際のズレ検証Calibration plot
- 再分類:Reclassification → 新しい因子を入れての分類能改善
- 臨床的有用性: clinical usefulness → Decision curve analysisなどに代表される、net benefitの計算
これらを順に説明していきます.なお、Reclassificationについては以前の記事を参照ください.なお、こちらに掲げる項目はSteybergらがその著書や論文(Epidemiology 2010)に紹介しています.
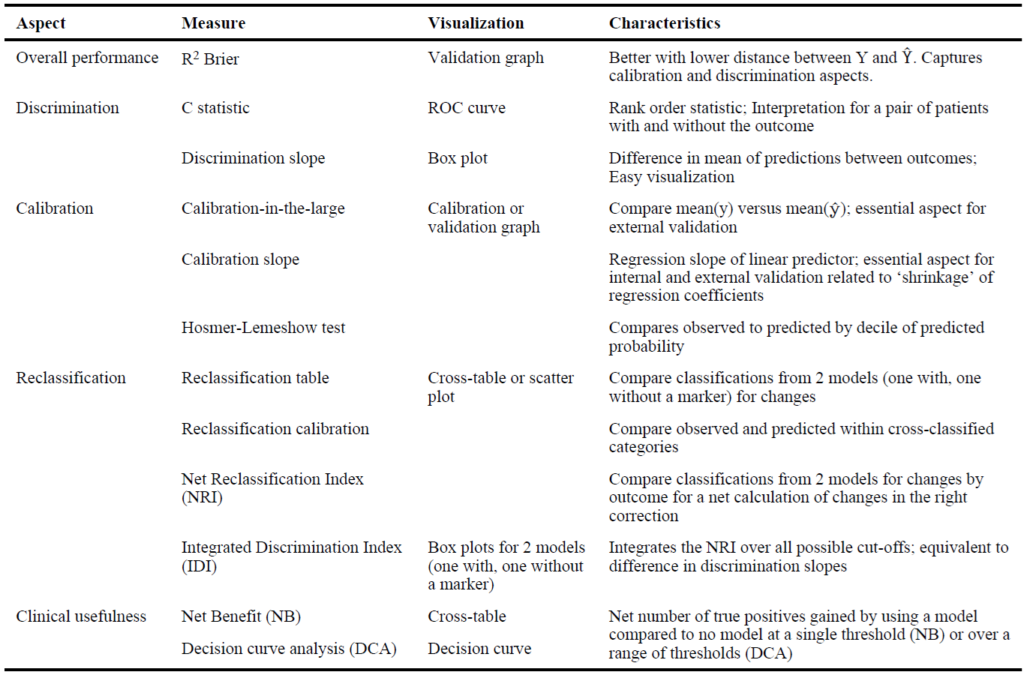
1.性能/適合度 Overall performance / Goodness-of-fit
適合度は「モデル全体としての当てはまりの良さ」を意味します.
“Distance between observed and predicted outcome” に関する客観的な指標を提供してくれます.
代表的な指標としては以下のようなものがあります.
- R square
- Akaike information criterion, AIC
- Bayesian information criterion, BIC
生存時間分析におけるGoodness-of-fitは、Cox-Snell残差を用いてモデルの適合性を評価します.
累積ハザード関数は、hazard rateが1の指数分布になることを利用して評価します.
具体的には、Cox-Snell残差とNelson-Aalen累積ハザード関数をグラフ化して、ハザード関数が45度の対角線に沿っていれば、近似的にハザード率1の指数分布となり、モデルがデータによく適合していることを意味します.
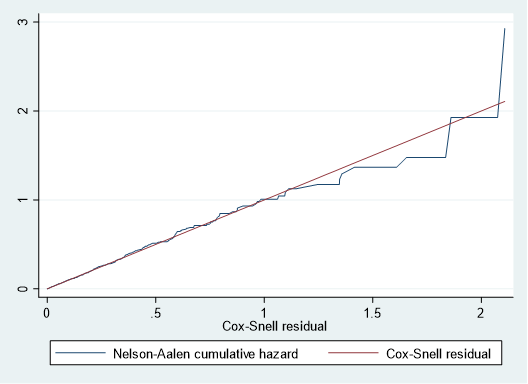
具体的にどのように行うかについては、UCLAのサイトに詳しく掲載されています。
2.判別 Discrimination
Discriminationは、アウトカムが二値変数のとき、予測モデルがアウトカムの有無を判別できる能力を評価する方法
Concordance index(C-index)の推定値であるC統計量が代表的な指標です.
グラフィカルに表現するのであれば、Area under curve (AUC)を作成しますが、これは横軸を感度、縦軸を1-特異度としてこれを連続的にプロットしていったものになります.

続いてC統計量の求め方です.ここでは代表的な多変量解析であるCox回帰とLogistic回帰について説明します.
Cox回帰
- アウトカム発生までの時間を考慮できる点で使い勝手よいモデルです.
- このモデルにおいては、Harrell’s C statistics を用います.
- Stcox から estat concordanceというコマンドを走らせれば終了なのですが、95%信頼区間が求められません.そこでSomers’Dを求めるコマンドであるsomersdを使用します.これは以前の記事で紹介していますね.
- その他、応用コマンドが整備されておらず、自作せねばならない点が難点です.
Logistic回帰
ROC曲線を描いて曲線下面積を求めます.具体的には、
- logistic outcome exposure1 exposure2…
- predict newvar, xb roctab outcome newvar, graph sum
Bootstrap resamplingをすることも簡単にできます.
- rocreg outcome var1, bseed(1000)
- rocregplot

3.較正 Calibration
予測と実際のずれがないかを確認します.適合度との違いがいまいち判然としませんが…。
これを実行するためには、ユーザーコマンドであるpmcalplotを使って実行します.
Stataではオリジナルコマンドは実装されていません(2021年9月現在).
このコマンドは生存時間分析だけではなくロジスティック回帰でも使うことができるため重宝しそうです。

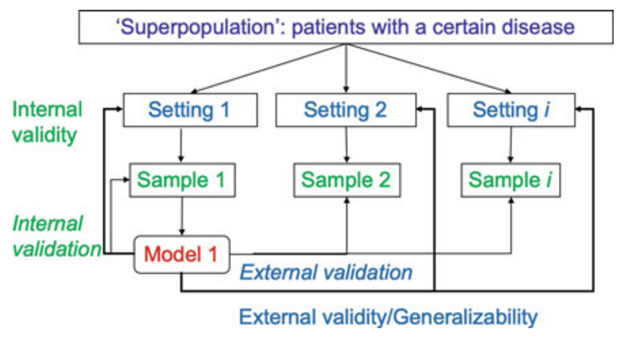
2.妥当性検証 Validation
妥当性は、内部妥当性と外部妥当性に分けられます.
内部妥当性とは、cross-validation法やbootstrap法を用いながらmodelの選択や各変数の重みづけの変更を繰り返すステップであり、まだモデルを作りこむ段階です.
一方で、外部妥当性とは、出来上がったモデルを外部のデータに当てはめるステップです.ここまで含めて予測モデルの研究です.
1.内的妥当性
同じデータセットでモデル構築と評価の両方を行うことをinternal validationと呼びます.
一般的には下記方法が知られています.
- Split sample法:例えば2:1などに分割する方法です。一般的には、症例数の多い方でモデルをいくつか作って他方で当てはめて検証します。その中でベストなモデルを選択します。サンプルサイズが限られているときに非効率で偏りが出るかもしれない、とされています(そうならないようにsplitしますが…)
- Fold cross-validation: 例えば9:1に分けて作成と検証を10回繰り返して平均した係数をモデルに組み込む方法です。似たような方法にLeave-one-out法があるが、これは1つずつ外してモデルを作り、最後に結果を統合する方法になります.
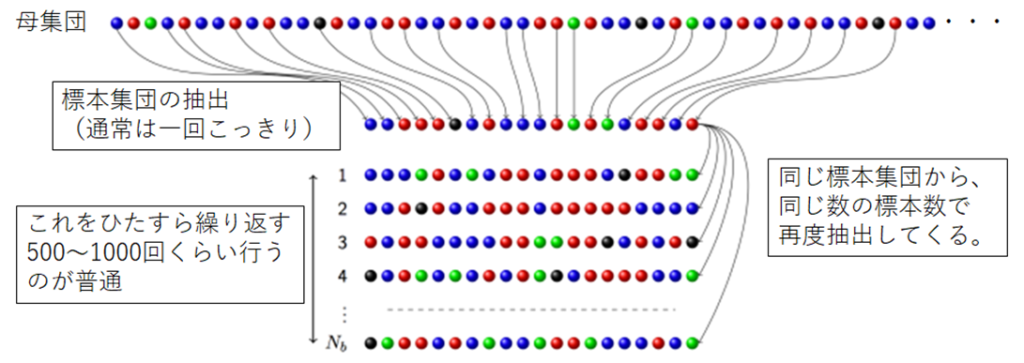
- Bootstrap法: 標本集団からもう一度標本抽出を行って疑似的な集団をいくつも作成する方法です.これを繰り返して変数選択や作成したモデルの性能を確認することができます.モデルの作成から検証までをBootstrapで実施することが必要なため、高度なプログラミング技術が必要です.
ここで、Bootstrap法についておさらいしておきましょう.
2.外的妥当性検証
外的妥当性(external validation)は、別の独立したサンプルをとってきて検証することを指します.
モデルの構築とは別プロセスで実施することが通常です.
外部の独立したサンプルをとってくる具体的な方法としては、
- Temporal validation: 時代で区切る
- Geographic validation: 別地域や別の病院
- Fully independent validation: 完全に異なるセッティングや国
です.バリデーションの概観を下図に示します.
3.落ち葉拾い
さて、ここまでは予測モデルの構築、バリデーションの具体的な方法論を述べてきましたが、ここからはStataでできることや参考文献などに関して、少しまとめてみたいと思います.
1.Stataコードの紹介
- stsplit: 生存時間分析の分析対象時間を、任意の時点で区切ることができます.観察期間がまちまちで、一部の症例しか長期的にフォローされていないような状況のときに、例えば5年以降を消す、とか、比例ハザード性が成り立たないときにpiecewiseに比例ハザードモデルを実行するときなどに便利です.
- stphtest: 比例ハザード性の確認の際に実施するコマンドの1つで、Schoenfeld残差プロットができます.連続変数のときにはこちらが便利です.カテゴリ変数のときはLog-log plotをstphplotで実行してください.統計学的アプローチが必要なときにはestat phtest, detailで一発です.
- splitsample: その名の通り、データセットを分けるのに使えます.rseed()オプションでシードを設定すれば再現性が得られます.主要なアウトカム数などバランスをとるように設定することもできます.
- somersd: そもそもSomer’s D statisticsを算出するためのコマンドですが、Harrel’s C statisticsを信頼区間付きで算出したり、異なるモデル間で比較したりするのに便利です.
2.参考文献
最後は参考文献です.TRIPOD声明は必須ですが、それ以外に個人的にわかりやすいと思ったものをご紹介いたします.
- Steyerberg. Clinical Prediction Models –A practical approach to development, validation, and updating- 2nd edition
- Steyerberg et al. Assessing the performance of prediction models: a framework for some traditional and novel measures. Epidemiology. 2010 January ; 21(1): 128–138
- Cowley et al. Methodological standards for the development and evaluation of clinical prediction rules: a review of the literature. Diagnostic and Prognostic Research (2019) 3:16
- https://stats.idre.ucla.edu/stata/seminars/stata-survival/#fit


コメント