
本カテゴリー「論文紹介」では管理者の独断と偏見と気まぐれで選んだ論文を解説します.
論文は図表の貼り付けや結果の細かな紹介はできませんが、最小限の結果(abstractで公開されている範囲)を引用する形で紹介していきます。また、図表もそのまま貼り付けることはせず、オリジナルのイメージ図に替えて掲載致します.
主旨としては管理者自らの疫学・統計学・臨床医学上の個人的解釈とし、Stataのコード紹介なども行っていきます.内容の詳細がご覧になりたい場合にはぜひ本文を正式に入手してください.
なお、内容の是非に踏み込んだコメントも致しますが、本ブログは情報提供だけを目的としたもので、医学的アドバイス(診断、治療、予防)の代わりになるものではありません。また診療目的でのアドバイスやご質問も受け付けておりませんので宜しくお願いいたします.
さて、今日ご紹介する論文は、「高次元傾向スコア」という手法を用いた研究をご紹介します.DOACを内服している腎機能低下患者のCVDリスクについての論文です.
Ashley J, et al. Risk of Cardiovascular Events and Mortality Among Elderly Patients With Reduced GFR Receiving Direct Oral Anticoagulants. Am J Kidney Dis. 2020 Sep;76(3):311-320. PMID: 32333946.
1.高次元傾向スコアとは
ここでいきなり聞いたこともない手法が出てきた!と思われた方のために簡単にご説明しますと、一言で言えば「傾向スコアの拡張版」です.
レセプト、電子カルテなどのいわゆる医療ビッグデータ解析に用いられることの多い、未測定交絡の対処方法の1つです.
通常のコホート研究では、可能な限り測定可能な交絡因子を測定していくことが基本でしたし、純粋に研究を目的とした情報収集においては当たり前のことだったわけです.しかしレセプトデータなどは入手できるデータが限られています.交絡因子がほとんど測定できない=ダメな研究という図式で語られてしまうことがあるのですが、たいていの場合、研究者は測定できる因子で代用して乗り越えたりしてきたわけです.
しかし未測定交絡となると話は別です.そこでこの手法が登場するわけです.膨大なデータであることを活かした研究手法であると言えるでしょう.
たくさんの情報を事前の情報や知識に基づかない方法で、機械的に選択して傾向スコア推定モデルに投入していくという方法を採ります.
具体的には数100~1000もの因子を複数の次元から選択してモデルを作ります.それで高次元傾向スコア、という呼び方になるんですね.次元というのはデータの種類のことを指します.同一のカテゴリに分類されるような病名、医薬品、診療行為、検査値などが次元になります.
2.論文の内容
1.データソース
カナダのオンタリオ州の65歳以上の地域住民の後ろ向きコホートで、2009年8月1日~2016年3月31日までのデータを使っています.オンタリオ州は一番大きな州で1300万もの人口を擁しています.この地域の住民はuniversal public health careにアクセスできるそうで、そういった人達のデータを丸ごと使えるような状況のようです.
患者基本情報、投薬情報、アウトカムデータを個人情報抜きの状態で連結したデータベースにしてそれを活用しているとのことです.
- 患者基本情報、バイタルサインなど:Ontario Registered Persons Database
- 投薬情報:Ontario Drug Benefit database
- すべての入院における診断・手技(日本で言うDPCデータみたいなもの):Canadian Institute for Health Information (CIHI) Discharge Abstract Database
- ERの診断情報:CIHI National Ambulatory Care Reporting System
- 検査データ:Ontario Laboratories Information System
- その他データ:Ontario Health Insurance Plan database
2.コホートのデザイン
データベース研究の基本の1つとして、デザインダイアグラムを描く、というのがあるのだそうです.こんな感じになるかなと思います.
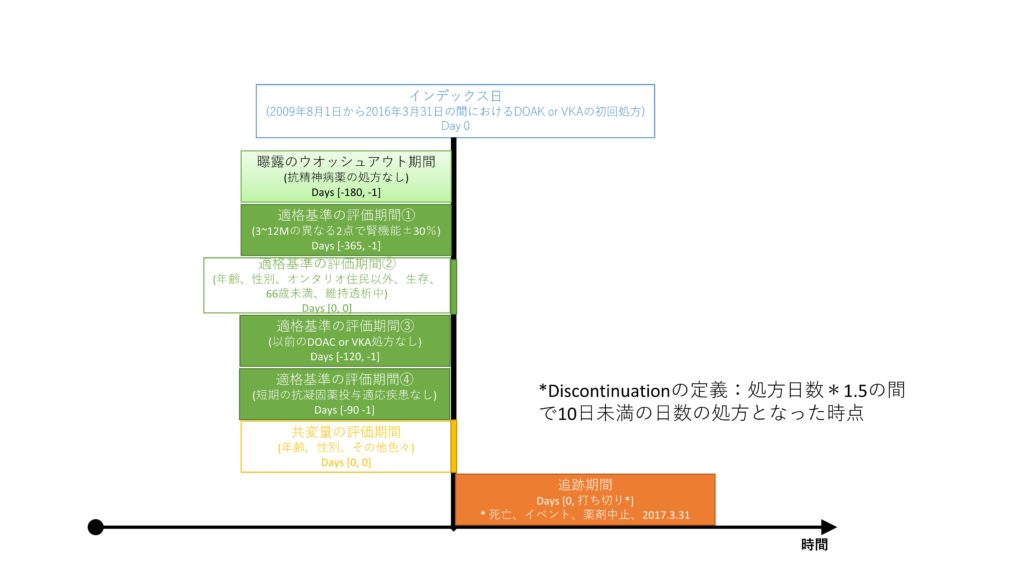
アウトカムは、CV複合イベントで、心筋梗塞、CABG、PCI実施、虚血性脳卒中のいずれかの発症または死亡です.
3.高次元傾向スコア
ここで真打ち登場なのですが、残念ながら論文中ではあまり詳しく述べられていません.
DOAC users were matched (greedy, without replacement) 1:1 to individuals with a VKA prescription on eGFR category and on the logit of the HDPS (±0.2 of the SD). Variables selected by the HDPS were inspected for appropriateness, with the top 500 covariates included based on multiplicative bias ranking.
statistical analysisより
ちょっとここは補足説明を入れないとわかりませんよね.とにかく500のコードを取り出してきて組み合わせてスコアを作ったんですよ、としか描かれてませんので.
高次元傾向スコアの作り方の手順は以下の通りです.
(1)次元の決定:使うデータセットの種類を決めます.処方、病名、検査項目等
(2)変数コードの抽出:次元毎に変数コードを決めます
(3)変数コードの出現回数の評価:対象期間で何%出現したか.各次元上位100~200個を候補として選択.
(4)バイアス評価:それぞれの変数と治療およびアウトカムとの関連を用いてどの程度偏りがあるかを評価
(5)変数の決定:バイアスの大きいものから上位500選択
(6)傾向スコアの推定:上記変数をロジスティック回帰により傾向スコアを推定
どの期間で出てきたコードをスコアに投入するのか、ということが記載されていませんでしたので、上の図の黄色のところは日数がよくわからない、ということになってしまいます.多くの研究ではindex dateから1年くらい遡ってコードをかき集めてきているみたいです.
4.結果
総じてDOAC群ではCV eventまたは死亡の複合イベント、CV event、出血いずれも抑制できている、という結果でした.
腎機能別では、eGFR が30以上だと出血リスクが有意に低く、CV eventまたは死亡の複合イベントではeGFR 30-60で有意に低いが、CV eventだけに絞るとむしろeGFR30未満で有意に低い、という結果でした.
Afとか深部静脈血栓などのより多めの投与量が必要な疾患がどのくらい紛れていたのかがわからない、というのがlimitationであると筆者達は述べていました.
まとめ
残念ながらStataではまだこの手法は実装できないようです.誰かが作ってくれるのを待つか、SASかRでやるか、というところでしょうか.どなたか情報提供してくださると助かります.


コメント